AI
Environmental Issues
Using ChatGPT is not bad for the environment
If you don't have time to read this post, these five graphs give most of the argument. Each includes both the energy/water cost of using ChatGPT in the moment and the amortized cost of training GPT-4:
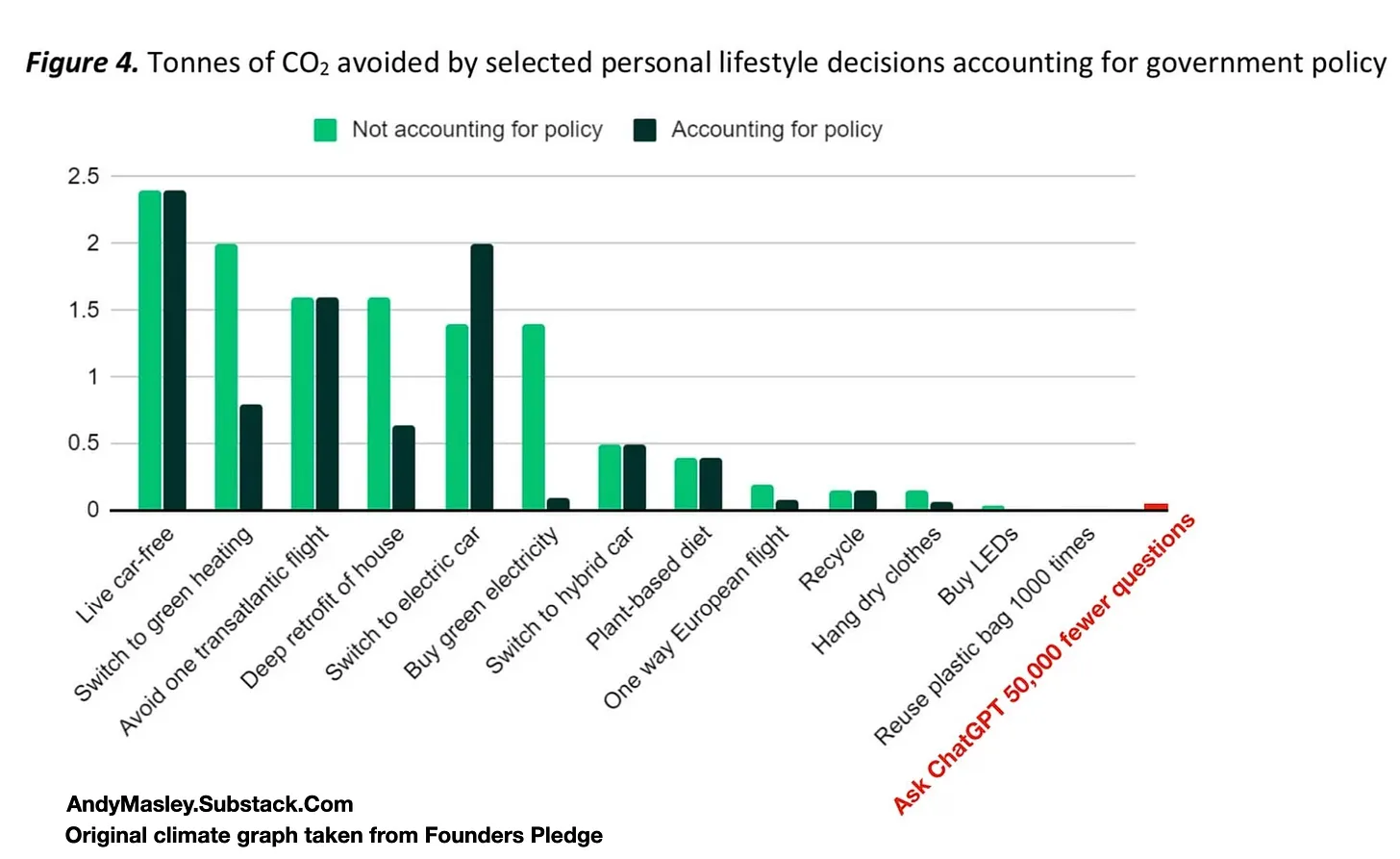
Source for original graph, I added the ChatGPT number. Each bar here represents 1 year of the activity, so the live car-free bar represents living without a car for just 1 year etc. The ChatGPT number assumes 3 Wh per search multiplied by average emissions per Wh in the US. Including the cost of training would raise the energy used per search by about 33% to 4 Wh. Some new data implies ChatGPT's energy might be 10x lower than this.
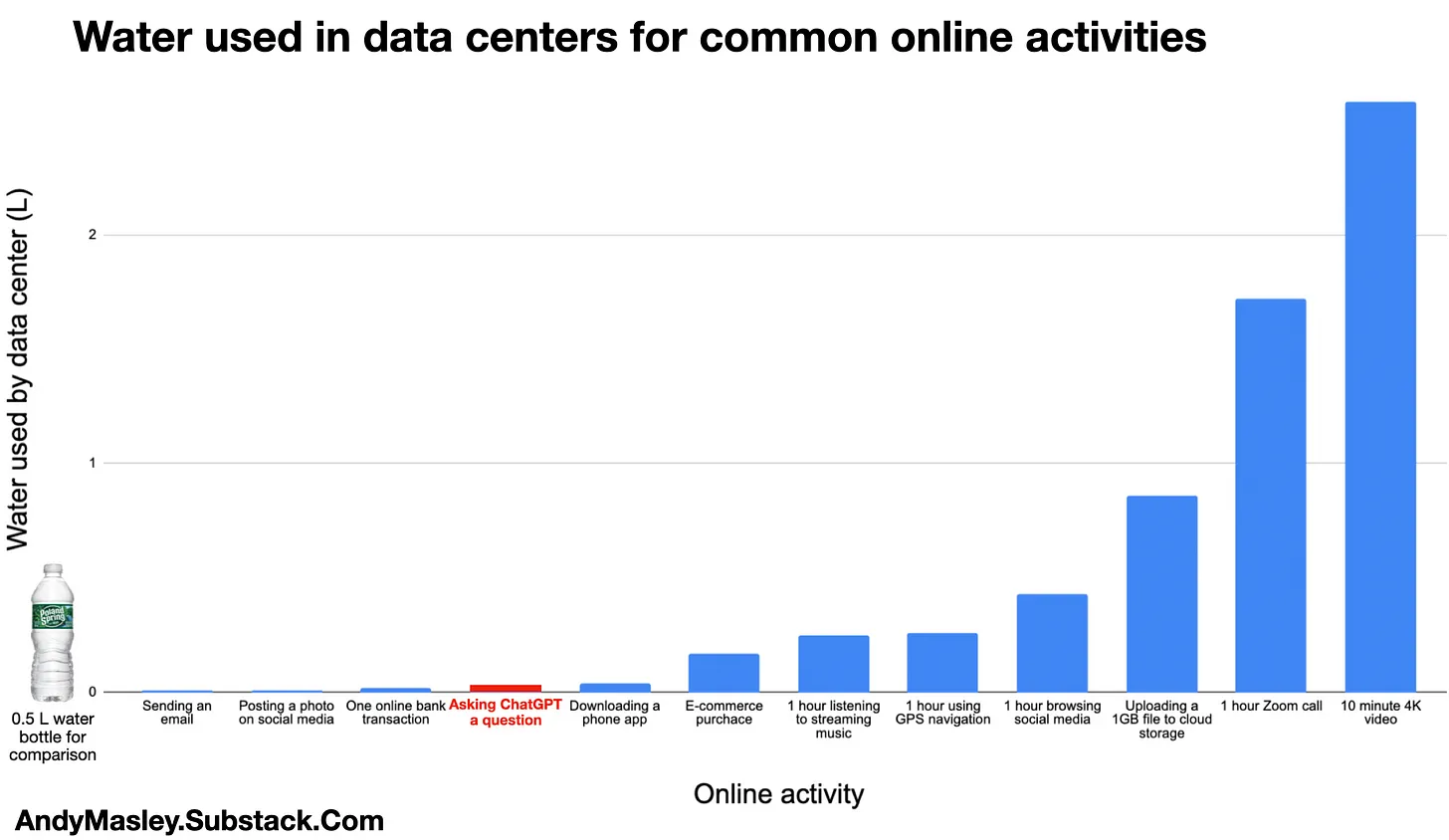
I got these numbers by multiplying the average rate of water used per kWh used in data centers + the average rate of water used generating the energy times the energy used in data centers by different tasks. The water cost of training GPT-4 is amortized into the cost of each search. This is the same method used to originally estimate the water used by a ChatGPT search. Note that water being “used” by data centers is ambiguous in general, read more in this section
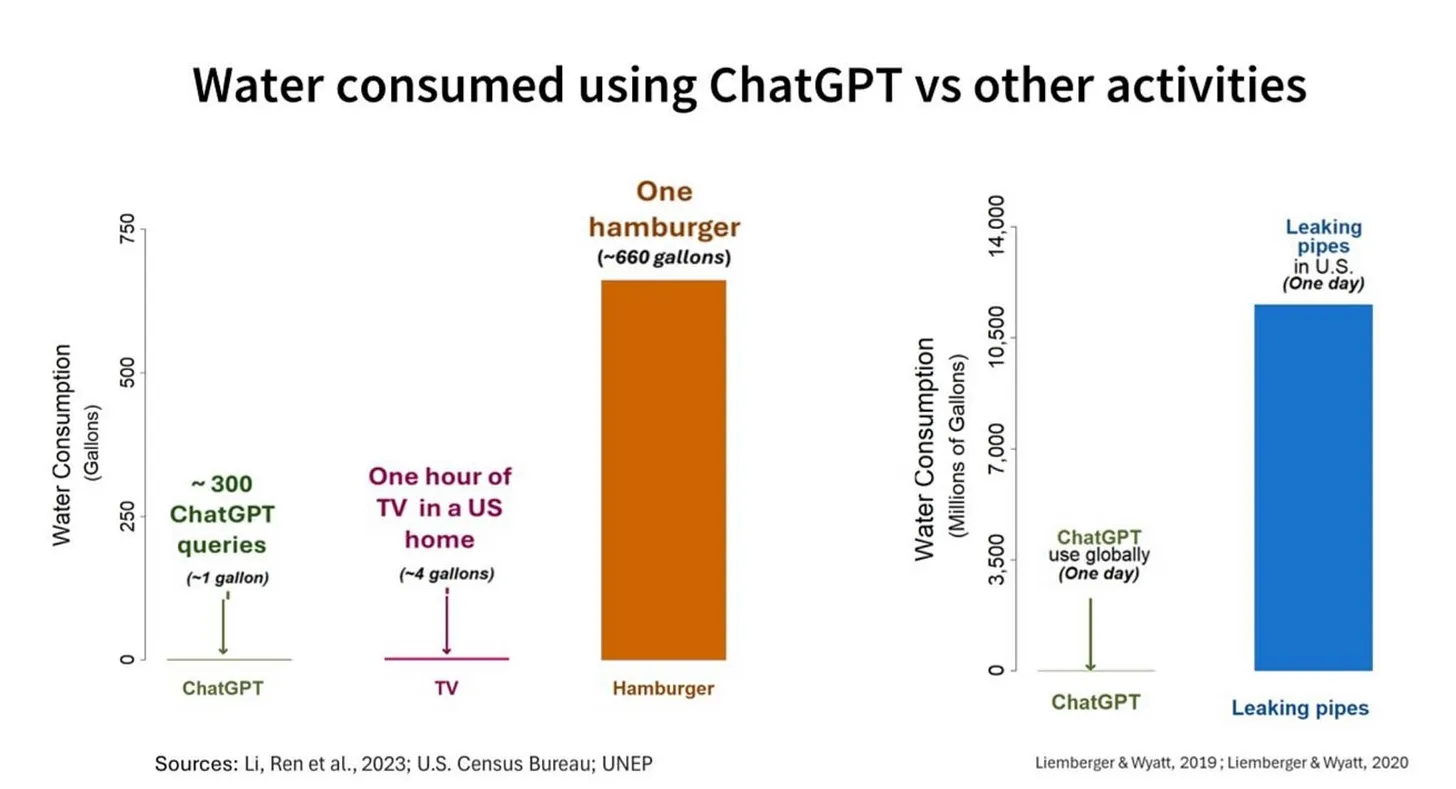
Statistic for a ChatGPT search, burger, and leaking pipes.
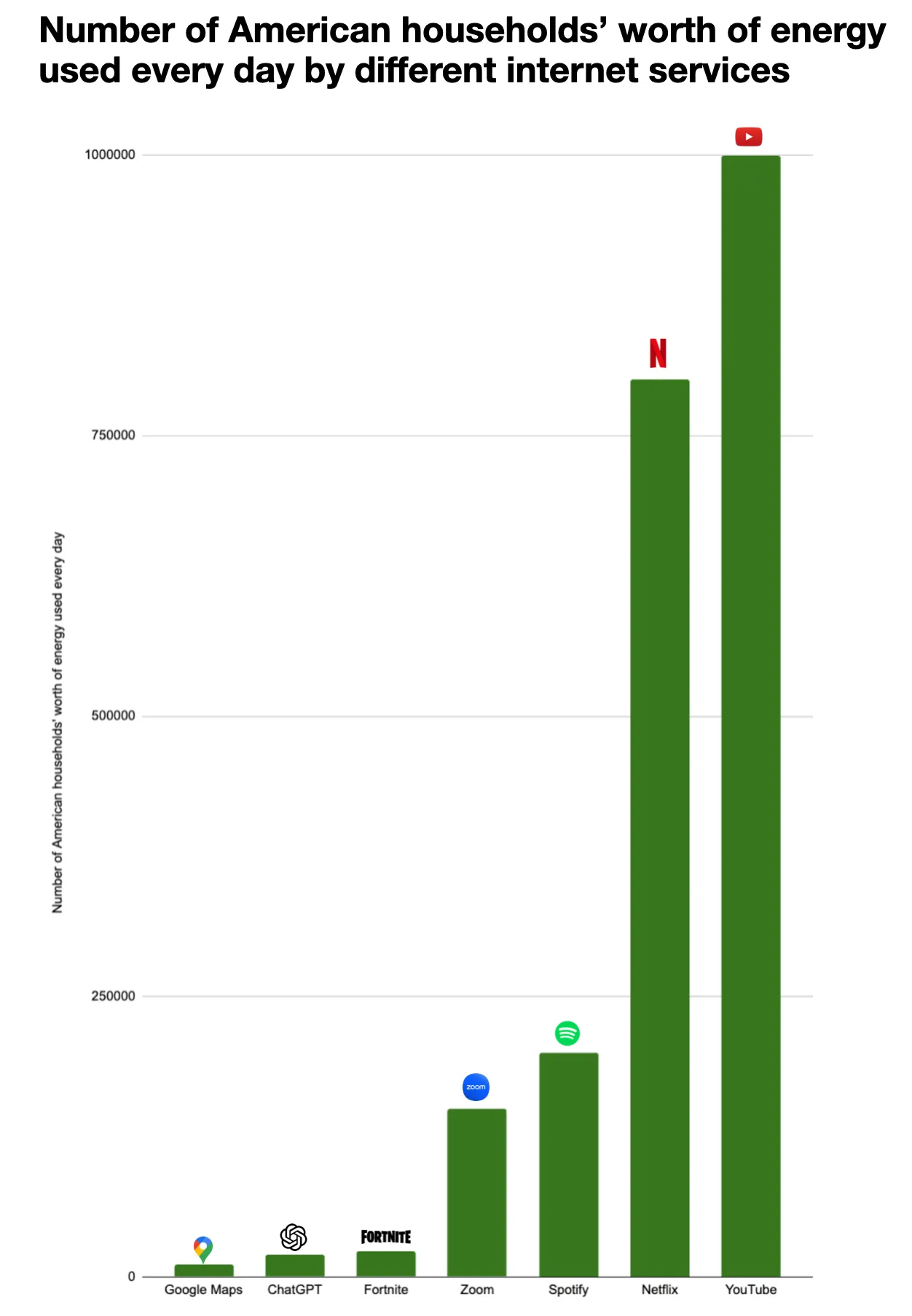
I got these numbers from back of the envelope calculations using publicly available data about each service. If you think they're wrong I'd be excited to update them! Because this is based on the total energy used by a service that's rapidly growing it's going to become outdated fast.
Back of the envelope calculation here
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
And it's crucial to note that, for instance, if you're using Google's AIs, which are both mixture of experts models (so inference is much cheaper) and run on Google's much more power efficient Tensor chips, it's probably less than this! Running a small AI locally is probably less efficient than running that same small AI in a data center, as well, but the AIs you can run locally are so much smaller than the ones you'd run in a data center that that counts as an optimization too, not to mention it decreases the power density and distortion that datacenters impose on the power grid.
Is AI eating all the energy? Part 1/2
I think this, especially in combination with "Using ChatGPT is not bad for the environment", is a really good demonstration of the idea that generative AI, in itself, is not a particularly power hungry or inefficient technology.
The different perspective this article takes that makes it worth adding in addition to "Using ChatGPT" is that it actually takes the time to aggregate the power usage of another industry no one seems to have a problem with the power consumption of — precisely because it's distributed, and thus mostly invisible usually — in this case the gaming industry, to give you a real sense of scale for those seemingly really high absolute numbers for AI work, and then to pile on even more, instead of comparing GenAI to common household and entertainment tasks as "Using ChatGPT" does, it more specifically compares using GenAI to save you time on a task versus doing all of it yourself — similar to this controversial paper.
Of course the natural response would be that the quality of the work that AI can do is not comparable to the quality of the work an invested human can do when really paying attention to every detail, which is true! But is it all or nothing? If AI is less energy intensive than a human at drawing and writing, then a human that's really pouring their heart and soul and craft into their writing or art but uses AI fill or has AI write some boilerplate or help them draft or critique their writing (thus saving a lot of sitting staring at the screen cycling things around) might save power on those specific sub-tasks. Moreover, do we really do that all the time? Or can AI be a reasonable timesaver for things we'd otherwise dash off and not pay too much attention to, thus acting as an energy-saver too?
Is AI eating all the energy? Part 2/2
This is the natural follow-up to the previous part of this article. In this, the author points out where the terrifying energy and water usage from AI is coming from. Not those using it, nor the technology itself inherently, but the reckless, insane, limitless "scale at all costs" (literally — and despite clearly diminishing returns) mindset of corporations caught up in the AI land grab:
This is the land rush: tech companies scrambling for control of commercial AI. […] The promises of huge returns from speculative investment breaks the safety net of rationalism.
[…] Every tech company is desperate to train the biggest and most expensive proprietary models possible, and they’re all doing it at once. Executives are throwing more and more data at training in a desperate attempt to edge over competition even as exponentially increasing costs yield diminishing returns.
[…]
And since these are designed to be proprietary, even when real value is created the research isn’t shared and the knowledge is siloed. Products that should only have to be created once are being trained many times over because every company wants to own their own.
[…]
In shifting away from indexing and discovery, Google is losing the benefits of being an indexing and discovery service. […] The user is in the best position to decide whether they need an AI or regular search, and so should be the one making that decision. Instead, Google is forcing the most expensive option on everyone in order to promote themselves, at an astronomical energy cost.
[…]
Another mistake companies are making with their AI rollouts is over-generalization. […] To maximize energy efficiency, for any given problem, you should use the smallest tool that works. […] Unfortunately, there is indeed a paradigm shift away from finetuned models and toward giant, general-purpose AIs with incredibly vast possibility spaces.
[…]
If you’re seeing something useful happening at all, that’s not part of the bulk of the problem. The real body of the problem is pouring enormous amounts of resources into worthless products and failed speculation.
The subtitle for that bloomberg article is “AI’s Insatiable Need for Energy Is Straining Global Power Grids”, which bothers me the more I think about it. It’s simply not true that the technology behind AI is particularly energy-intensive. The technology isn’t insatiable, the corporations deploying it are. The thing with an insatiable appetite for growth at all cost is unregulated capitalism.
So the lesson is to only do things if they’re worthwhile, and not to be intentionally wasteful. That’s the problem. It’s not novel and it’s not unique to AI. It’s the same simple incentive problem that we see so often.
[…] Individual users are — empirically — not being irresponsible or wasteful just by using AI. It is wrong to treat AI use as a categorical moral failing […] blame for these problems falls squarely on the shoulders of the people responsible for managing systems at scale. […] And yet visible individuals who aren’t responsible for the problems are being blamed for the harm caused by massive corporations in the background […] it removes moves the focus from their substantial contribution to the problem to an insubstantial one they’re not directly responsible for.
It’s the same blame-shifting propaganda we see in recycling, individual carbon footprints, etc.
Reactions to MIT Technology Review's report on AI and the environment
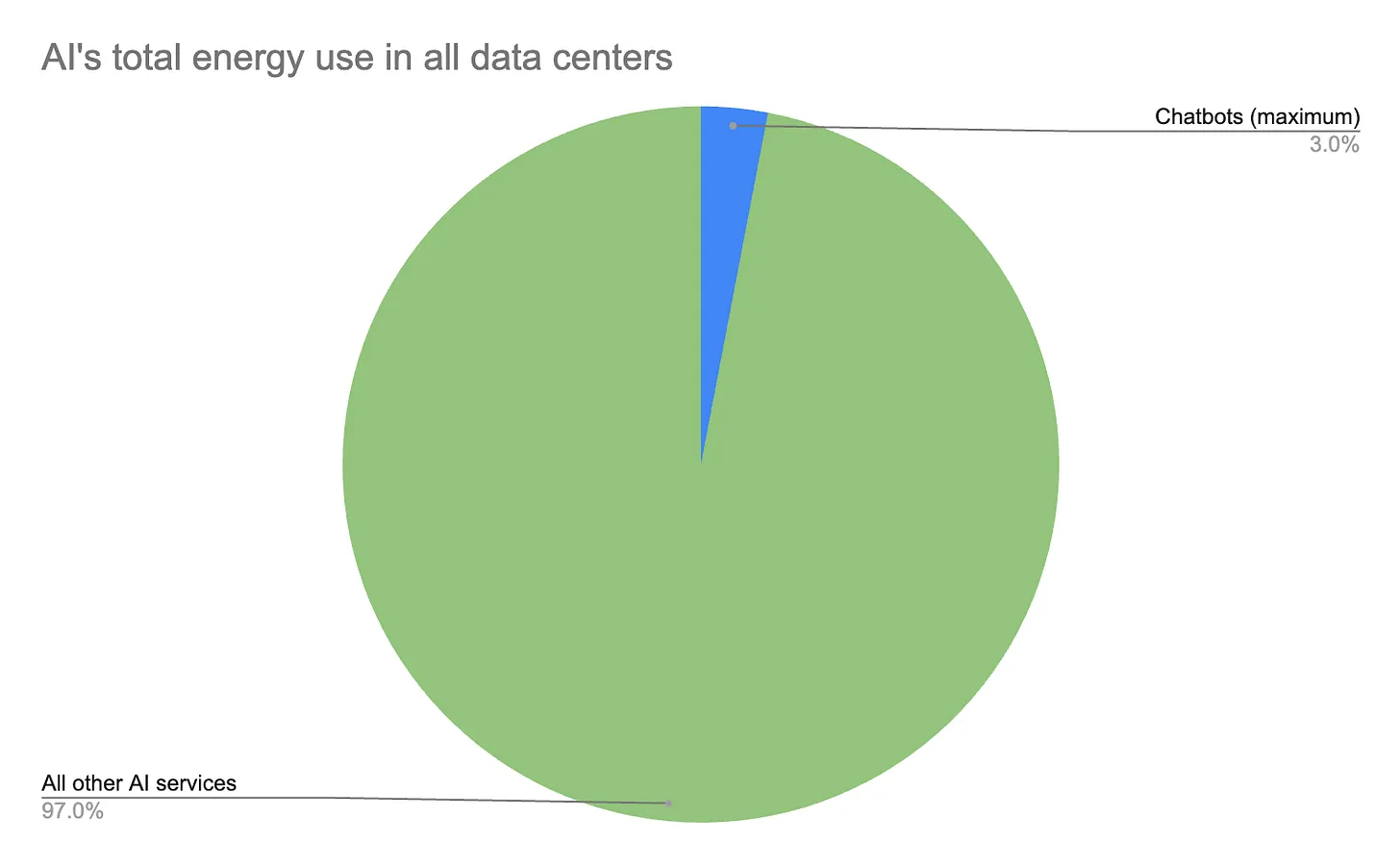
A new report from MIT Technology Review on AI's energy usage is being touted by anti-AI people as proof they were right. In actuality, its numbers line up very nicely with the defenses of AI's energy usage that we've been seeing — so why are people confused? Because they presented their data in an extremely misleading way:
The next section gives an example of how using AI could make your daily energy use get huge quick. Do you notice anything strange?
So what might a day’s energy consumption look like for one person with an AI habit?
Let’s say you’re running a marathon as a charity runner and organizing a fundraiser to support your cause. You ask an AI model 15 questions about the best way to fundraise.
Then you make 10 attempts at an image for your flyer before you get one you are happy with, and three attempts at a five-second video to post on Instagram.
You’d use about 2.9 kilowatt-hours of electricity—enough to ride over 100 miles on an e-bike (or around 10 miles in the average electric vehicle) or run the microwave for over three and a half hours.
Reading this, you might think “That sounds crazy! I should really cut back on using AI!”
Let’s read this again, but this time adding the specific energy costs of each action, using the report’s estimates for each:
Let’s say you’re running a marathon as a charity runner and organizing a fundraiser to support your cause. You ask an AI model 15 questions about the best way to fundraise. (This uses 29 Wh)
Then you make 10 attempts at an image for your flyer before you get one you are happy with (This uses 12 Wh) and three attempts at a five-second video to post on Instagram (This uses 2832 Wh)
You’d use about 2.9 kilowatt-hours of electricity—enough to ride over 100 miles on an e-bike (or around 10 miles in the average electric vehicle) or run the microwave for over three and a half hours.
Wait a minute. One of these things is not like the other. Let’s see how these numbers look on a graph:
Of the 2.9 kilowatt-hours, 98% is from the video!
This seems like saying “You buy a pack of gum, and an energy drink, and then a 7 course meal at a Michelin Star restaurant. At the end, you’ve spend $315! You just spent so much on gum, an energy drink, and a seven course meal at a Michelin Star restaurant.” This is the wrong message to send readers. You should be saying “Look! Our numbers show that your spending on gum and energy drinks don’t add to much, but if you’re trying to save money, skip the restaurant.”
Mistral environmental impact study
This is excellent work on the part of Mistral:
After less than 18 months of existence, we have initiated the first comprehensive lifecycle analysis (LCA) of an AI model, in collaboration with Carbone 4, a leading consultancy in CSR and sustainability, and the French ecological transition agency (ADEME). To ensure robustness, this study was also peer-reviewed by Resilio and Hubblo, two consultancies specializing in environmental audits in the digital industry.
I'm excited that finally, at least one decently sized relatively frontier AI company has finally, actually, been thorough, complete, and open on this matter, not just cooperating with an independent sustainability consultancy, but also the French environmental agency and two separate independent environmental auditors. This is better than I had hoped for prior!
The lifecycle analysis is almost hilariously complete, too, encompassing:
- Model conception
- Datacenter construction
- Hardware manufacturing, transportation, and maintenence/replacement
- Model training and inference (what people usually look at)
- Network traffic in serving model tokens
- End-user equipment while using the models
Basically, the study concludes that generating 400 tokens costs 1.14g of CO_2, 0.05L of water, and 0.2mg Sb eq of non-renewable materials. Ars Technica puts some of these figures into perspective well:
Mistral points out, for instance, that the incremental CO2 emissions from one of its average LLM queries are equivalent to those of watching 10 seconds of a streaming show in the US (or 55 seconds of the same show in France, where the energy grid is notably cleaner).
This might seem like a lot until you realize that the average query length they're using (from the report) is 400 tokens, and Mistral Large 2 (according to OpenRouter) generates tokens at about 35 tok/s, so those 400 tokens would take 11 seconds to generate, which means that this isn't increasing the rate of energy consumption of an average internet user at all.
It's also equivalent to sitting on a Zoom call for anywhere from four to 27 seconds, according to numbers from the Mozilla Foundation. And spending 10 minutes writing an email that's read fully by one of its 100 recipients emits as much CO2 as 22.8 Mistral prompts, according to numbers from Carbon Literacy.
So as long as using AI saves you more than 26 seconds out of 10 minutes writing an email, it's actually saved the environment. (10 / 22.8 = 0.43, 0.43*60 = 25.8, so a Mistral prompt is equivalent in power usage to 25.8s of writing an email yourself in terms of CO2 output).
Meanwhile, training the model and running it for 18 months used 20.4 ktCO_2, 281,000 m^3 of water, and 660 kg Sb eq of resource depletion. Once again, Ars Technica puts this in perspective:
20.4 ktons of CO2 emissions (comparable to 4,500 average internal combustion-engine passenger vehicles operating for a year, according to the Environmental Protection Agency) and the evaporation of 281,000 cubic meters of water (enough to fill about 112 Olympic-sized swimming pools [or about the water usage of 500 Americans for a year]).
That sounds like a lot, but it's the same fallacy I've pointed out over and over when people discuss AI's environmental issues: the fallacy of aggregation. It sounds gigantic, but in comparison to the number of people it benefits, it is absolutely and completely dwarfed; moreover, there are a million other things we do regularly without going into a moral panic over it — such as gaming — that, when aggregated in the same way, use much more energy.
What this further confirms, then, in my opinion, the point that compared to a lot of other common internet tasks that we do — including streaming and video calls and stuff like that — AI is basically nothing. And even for tasks that are basically directly equivalent like composing an email manually versus composing it with the help of an AI, it actually uses less CO2 and water to do it via the AI. Basically: the more optimistic, rational, middle of the road estimates of AI climate impact, which till now had to make do only with estimated data, are further confirmed to be correct.
They emphasize, of course, that with millions or billions of people prompting these models, that small amount can add up. But by the same token, those more expensive common local or internet computer tasks that we already do without thinking would add up to even more. And it's worth pointing out that the CO2 emitted and water used by this AI with millions of people prompting it a lot is the equivalent of like 4,500 people owning a car for a year. *That's nothing in comparison to the size of the user base.
What's worth noting for this analysis is that they did it for their Mistral Large 2 model. This model is significantly smaller than a lot of frontier open weight models in its price bracket at 123B parameters versus the usual 200-400B, but it is dense, meaning that training and inference requires all parameters to be active and evaluated to produce an output, whereas almost all modern frontier models are mixture of experts, with only about 20-30B parameters typically active. This means that Mistral Large 2 likely used around 4-5 times more energy and water to train and run inferences with compared to top of the line competing models. So put that in your hat.
The big issue with AI continues to be the concentration of environmental and water usage in particular communities, and the reckless and unnecessary scaling of AI datacenters by the hyperscalers.
Mistral does have some really good suggestions for improving the environmental efficiency of models themselves, though, besides just waiting for the AI bubble to pop:
These results point to two levers to reduce the environmental impact of LLMs.
- First, to improve transparency and comparability, AI companies ought to publish the environmental impacts of their models using standardized, internationally recognized frameworks. Where needed, specific standards for the AI sector could be developed to ensure consistency. This could enable the creation of a scoring system, helping buyers and users identify the least carbon-, water- and material-intensive models.
Second, from the user side, encouraging the research for efficiency practices can make a significant difference:
- developing AI literacy to help people use GenAI in the most optimal way,
- choosing the model size that is best adapted to users’ needs,
- grouping queries to limit unnecessary computing,
For public institutions in particular, integrating model size and efficiency into procurement criteria could send a strong signal to the market.
The AI water issue is fake: On the national, local, and personal level
This fourteen thousand word essay is one of the most thorough dismantlements of something I've ever seen in my life. Not only does he annihilate the argument that data centers use much water at all at /every single level, from the national to the county level (what most people are worried about) to the level of personal environmental responsibility, providing ample sources and calculations, as well as excellent graphs and comparisons to give you clear context, he provides a comprehensive debunking of every single major AI-data-center-water-usage-related headline that's come out in the last few years. Seriously. Anytime anyone brings up this stupid shit again, I'll just point them here. I checked a significant sampling of his sources and math, and besides one math error, it seems rock solid. Someone on lobste.rs (a Hacker News alternative where people hate AI with a burning passion) even tried to "debunk" him (in the typical dismissive, ignorant way anti-AI people like to do) and he was able to so comprehensively and thoroughly respond that they retracted their criticisms.
AI data centers use water. Like any other industry that uses water, they require careful planning. If an electric car factory opens near you, that factory may use just as much water as a data center. The factory also requires careful planning. But the idea that either the factory or AI is using an inordinate amount of water that merits any kind of boycott or national attention as a unique serious environmental issue is innumerate. On the national, local, and personal level, AI is barely using any water, and unless it grows 50 times faster than forecasts predict, this won’t change. I’m writing from an American context and don’t know as much about other countries. But at least in America, the numbers are clear and decisive.
The idea that AI’s water usage is a serious national emergency caught on for three reasons:
- People get upset at the idea of a physical resource like water being spent on a digital product, especially one they don’t see value in, and don’t factor in just how often this happens everywhere.
- People haven’t internalized how many other people are using AI. AI’s water use looks ridiculous if you think of it as a small marginal new thing. It looks tiny when you divide it by the hundreds of millions of people using AI every day.
- People are easily alarmed by contextless large numbers, like the number of gallons of water a data center is using. They compare these large numbers to other regular things they do, not to other normal industries and processes in society.
Together, these create the impression that AI water use is a problem. It is not. Regardless of whether you love or hate AI, it is not possible to actually look at the numbers involved without coming to the conclusion that this is a fake problem. This problem’s hyped up for clicks by a lot of scary articles that completely fall apart when you look at the simple easy-to-access facts on the ground. These articles have contributed to establishing fake “common wisdom” among everyday people that AI uses a lot of water.
This post is not at all about other issues related to AI, especially the very real problems with electricity use. I want to give you a complete picture of the issue. I think AI and the national water system are both so wildly interesting that they can be really fun to read about even if you’re not invested in the problem.
Empire of AI is wildly misleading about AI water use
I was taking a break from posting about AI and the environment, but after reading parts of Karen Hao’s book Empire of AI, I’ve stumbled on such wildly misleading claims that have so far gone unaddressed that I’ve felt the need to counter them here. Within 20 pages, Hao manages to:
- Claim that a data center is using 1000x as much water as a city of 88,000 people, where it’s actually using about 0.22x as much water as the city, and only 3% of the municipal water system the city relies on. She’s off by a factor of 4500. This is the single largest error in any popular book that I’ve found on my own, and to my knowledge I’m the first person to notice it.
- Imply that AI data centers will consume 1.7 trillion gallons of drinkable water by 2027, while the study she’s pulling from says that only 3% of that will be drinkable water, and 90% will not be consumed, and instead returned to the source unaffected.
- Paint a picture of AI data centers harming water access in America, where they don’t seem to have caused any harm at all.
- Frame Uruguay as using an unacceptable amount of water on industry and farming, where it actually seems to use the same ratio as any other country.
- Frame the Uruguay proposed data center as using a huge portion of the region’s water where it would actually use ~0.3% of the municipal water system, without providing any clear numbers.
These are all the significant mentions of data centers using water in the book. Read in this light, the chapter becomes somewhat ridiculous, because the rest includes descriptions of brutal acts of torture and plunder under colonialism, and then frames data center water use as a continuation of that same colonialism. If instead you see data centers using water in other countries as part of a simple trade the countries are making to get more taxable industry in the area, and that doesn’t seem to harm water access, the central narrative thrust of the chapter becomes false.
IP Issues
“Wait, not like that”: Free and open access in the age of generative AI
The whole article is extremely worth reading for the full arguments, illustrations, and citations, and mirrors my feelings well, but here's just the thesis:
The real threat isn’t AI using open knowledge — it’s AI companies killing the projects that make knowledge free.
The visions of the open access movement have inspired countless people to contribute their work to the commons: a world where “every single human being can freely share in the sum of all knowledge” (Wikimedia), and where “education, culture, and science are equitably shared as a means to benefit humanity” (Creative Commons).
But there are scenarios that can introduce doubt for those who contribute to free and open projects like the Wikimedia projects, or who independently release their own works under free licenses. I call these “wait, no, not like that” moments.
[…]
These reactions are understandable. When we freely license our work, we do so in service of those goals: free and open access to knowledge and education. But when trillion dollar companies exploit that openness while giving nothing back, or when our work enables harmful or exploitative uses, it can feel like we've been naïve. The natural response is to try to regain control.
This is where many creators find themselves today, particularly in response to AI training. But the solutions they're reaching for — more restrictive licenses, paywalls, or not publishing at all — risk destroying the very commons they originally set out to build.
The first impulse is often to try to tighten the licensing, maybe by switching away to something like the Creative Commons’ non-commercial (and thus, non-free) license. […]
But the trouble with trying to continually narrow the definitions of “free” is that it is impossible to write a license that will perfectly prohibit each possibility that makes a person go “wait, no, not like that” while retaining the benefits of free and open access. If that is truly what a creator wants, then they are likely better served by a traditional, all rights reserved model in which any prospective reuser must individually negotiate terms with them; but this undermines the purpose of free […]
What should we do instead? Cory Doctorow has some suggestions:
Our path to better working conditions lies through organizing and striking, not through helping our bosses sue other giant mulitnational corporations for the right to bleed us out.
The US Copyright Office has repeatedly stated that AI-generated works don't qualify for copyrights […]. We should be shouting this from the rooftops, not demanding more copyright for AI.
[…]
Creative workers should be banding together with other labor advocates to propose ways for the FTC to prevent all AI-based labor exploitation, like the "reverse-centaur" arrangement in which a human serves as an AI's body, working at breakneck pace until they are psychologically and physically ruined:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
As workers standing with other workers, we can demand the things that help us, even (especially) when that means less for our bosses. On the other hand, if we confine ourselves to backing our bosses' plays, we only stand to gain whatever crumbs they choose to drop at their feet for us.
If Creators Suing AI Companies Over Copyright Win, It Will Further Entrench Big Tech
There’s been this weird idea lately, even among people who used to recognize that copyright only empowers the largest gatekeepers, that in the AI world we have to magically flip the script on copyright and use it as a tool to get AI companies to pay for the material they train on. […] because so many people think that they’re supporting creators and “sticking it” to Big Tech in supporting these copyright lawsuits over AI, I thought it might be useful to play out how this would work in practice. And, spoiler alert, the end result would be a disaster for creators, and a huge benefit to big tech. It’s exactly what we should be fighting against.
And, we know this because we have decades of copyright law and the internet to observe. Copyright law, by its very nature as a monopoly right, has always served the interests of gatekeepers over artists. This is why the most aggressive enforcers of copyright are the very middlemen with long histories of screwing over the actual creatives: the record labels, the TV and movie studios, the book publishers, etc.
This is because the nature of copyright law is such that it is most powerful when a few large entities act as central repositories for the copyrights and can lord around their power and try to force other entities to pay up. This is how the music industry has worked for years, and you can see what’s happened. […]
[…] The almost certain outcome (because it’s what happens every other time a similar situation arises) is that there will be one (possibly two) giant entities who will be designated as the “collection society” with whom AI companies will […] just purchase a “training license” and that entity will then collect a ton of money, much of which will go towards “administration,” and actual artists will… get a tiny bit.
[…]
But, given the enormity of the amount of content, and the structure of this kind of thing, the cost will be extremely high for the AI companies […] meaning that only the biggest of big tech will be able to afford it.
In other words, the end result of a win in this kind of litigation […] would be the further locking-in of the biggest companies. Google, Meta, and OpenAI (with Microsoft’s money) can afford the license, and will toss off a tiny one-time payment to creators […].
Creative Commons: AI Training is Fair Use
The Creative Commons makes a detailed and in my opinion logically and philosophically sound, if perhaps not necessarily legally sound (we'll see; I'm not a lawyer, and these things are under dispute in courts currently, although it does seem like things are turning towards AI training being fair use) argument that AI training should be considered fair use.
Algorithmic Underground
There have been innumerable smug, ressentiment-tinged, idiotic, joyless, hollow, soulless thinkpieces tech bros have written about "democratizing" art — or worse, but disturbingly often, finally killing off artists careers and human art entirely, although most of those are Xitter threads, Reddit comments, and memes, since only a bare few can muster sustained literacy. There have also been equally uncountable and slightly more sympathetic, yet also frustrating and ultimately contemplation and content-free panicked, angry, reactionary articles by artists on the subject matter, motivated to write (or draw, as the case may be) because they're more dedicated to defending a shortsighted notion of their craft or livelihood than real moral principles, even such important ones as open access, freedom of information, and freedom of innovation. This is one of the few essays on the matter that I've actually found insightful and worth reading.
I have been thinking about something Jean Baudrillard said a lot recently… Prior to the current moment, I believed he was more cynical than necessary. [Now I find] myself wondering if we might actually bring about… a future where art dies.
"Art does not die because there is no more art. It dies because there is too much."
— Jean Baudrillard
[relocated for flow when conveying the central point of the essay:] As of recently, we live in a world where computers can generate art that is so good we now struggle with distinguishing between art made by humans and art made by algorithms. And more, the new systems can generate the works almost instantly… From a purely practical perspective, skilled humans may not be necessary the same way they have been up to now… [but] I don’t worry about art dying…
Artists Gonna Art
Baudrillard… worries that great art will get lost in the sea of noise created by a flood of ordinary art…
Wait a sec… did he just say we’re losers with nothing interesting to say?! Screw that guy! Why should we care what he thinks?! Maybe we want to hide in the sea of noise? Maybe we don’t care about the mainstream?! Maybe that isn’t where we want to be at all! Maybe we are different because our ideas are better?!
For creative folks, the rebellion is automatic. It is a side effect of being different enough to have experiences that require defending a nonconsensus view…
Being creative alone can be satisfying, but being creative with others is extraordinary. The things we create can become something bigger than any individual when several perspectives work together.
Finding other people comfortable with a constant flow of ideas is frustrating… Artistic communities can be built around groups of creative folks that are sick of that experience… They pride themselves on the way they diverge from the norm…
These communities go by different names. Sometimes they’re called scenes, like the NYC art scene during the 70’s or Connecticut hardcore…
Art and Art Forms
…
Humans have been making art for a long time. There are neanderthal cave drawings in France that go back 57,000 years. The oldest known “representational” art is an Indonesian cave painting of a pig that goes back 45,500 years. The oldest known depiction of a human, the Venus of Hohle Fels, is from 40,000 years ago.
I struggle to believe that humans will stop expressing themselves anytime soon, let alone while I’m here to see it, so I don’t believe art will stop being made. The mediums we use to create art, or art forms, are different. They are more transient. They exist as one of the possible ways humans can express themselves. Art forms can die.…
Hiding In The Data
…models find the clearest signals in data around the patterns that represent a kind of mainstream…
As any creative knows, the popularity of some idea is quite different from how important it is…
Whenever it’s true that important ideas that are not well known can live alongside important ideas that are consensus, it is also true that unique communities can exist alongside much bigger mainstream communities without drawing much attention to themselves.
…It makes me wonder if there is a way for creatives outside the mainstream to leverage obscurity in ways I haven’t thought about yet… I find that exciting…
What I’m most interested in are approaches for creating art that becomes increasingly obscure as more is made. I want to understand how art can survive in a world where all of our work might be downloaded for use as training data, yet the AIs created cannot produce new work based on ours. I feel as though what I want is to build underground art scenes where the definition of underground is based on whether or not an AI can reliably copy it. If it can, maybe the art isn’t original enough, or something like that.
Maybe we want to hide in the sea of noise? Maybe we don’t care about the mainstream?! Maybe that isn’t where we want to be at all! Maybe we are different because our ideas are better?!
Architecture and Design
On Chomsky and the Two Cultures of Statistical Learning
At the Brains, Minds, and Machines symposium held during MIT’s 150th birthday party in 2011, Technology Review reports that Prof. Noam Chomsky "derided researchers in machine learning who use purely statistical methods to produce behavior that mimics something in the world, but who don’t try to understand the meaning of that behavior."
[…]
I take Chomsky's points to be the following:
- Statistical language models have had engineering success, but that is irrelevant to science.
- Accurately modeling linguistic facts is just butterfly collecting; what matters in science (and specifically linguistics) is the underlying principles.
- Statistical models are incomprehensible; they provide no insight.
- Statistical models may provide an accurate simulation of some phenomena, but the simulation is done completely the wrong way; people don't decide what the third word of a sentence should be by consulting a probability table keyed on the previous words, rather they map from an internal semantic form to a syntactic tree-structure, which is then linearized into words. This is done without any probability or statistics.
- Statistical models have been proven incapable of learning language; therefore language must be innate, so why are these statistical modelers wasting their time on the wrong enterprise?
Is he right? That's a long-standing debate. These are my short answers:
- I agree that engineering success is not the sole goal or the measure of science. But I observe that science and engineering develop together, and that engineering success shows that something is working right, and so is evidence (but not proof) of a scientifically successful model.
- Science is a combination of gathering facts and making theories; neither can progress on its own. In the history of science, the laborious accumulation of facts is the dominant mode, not a novelty. The science of understanding language is no different than other sciences in this respect.
- I agree that it can be difficult to make sense of a model containing billions of parameters. Certainly a human can't understand such a model by inspecting the values of each parameter individually. But one can gain insight by examing the properties of the model—where it succeeds and fails, how well it learns as a function of data, etc.
- I agree that a Markov model of word probabilities cannot model all of language. It is equally true that a concise tree-structure model without probabilities cannot model all of language. What is needed is a probabilistic model that covers words, syntax, semantics, context, discourse, etc. Chomsky dismisses all probabilistic models because of shortcomings of a particular 50-year old probabilistic model. […] Many phenomena in science are stochastic, and the simplest model of them is a probabilistic model; I believe language is such a phenomenon and therefore that probabilistic models are our best tool for representing facts about language, for algorithmically processing language, and for understanding how humans process language.
- In 1967, Gold's Theorem showed some theoretical limitations of logical deduction on formal mathematical languages. But this result has nothing to do with the task faced by learners of natural language. In any event, by 1969 we knew that probabilistic inference (over probabilistic context-free grammars) is not subject to those limitations (Horning showed that learning of PCFGs is possible). I agree with Chomsky that it is undeniable that humans have some innate capability to learn natural language, but we don't know enough about that capability to say how it works; it certainly could use something like probabilistic language representations and statistical learning. And we don't know if the innate ability is specific to language, or is part of a more general ability that works for language and other things.
The rest of this essay consists of longer versions of each answer.
[…]
Chomsky said words to the effect that statistical language models have had some limited success in some application areas. Let's look at computer systems that deal with language, and at the notion of "success" defined by "making accurate predictions about the world." First, the major application areas […] Now let's look at some components that are of interest only to the computational linguist, not to the end user […]
Clearly, it is inaccurate to say that statistical models (and probabilistic models) have achieved limited success; rather they have achieved an overwhelmingly dominant (although not exclusive) position. […]
This section has shown that one reason why the vast majority of researchers in computational linguistics use statistical models is an engineering reason: statistical models have state-of-the-art performance, and in most cases non-statistical models perform worst. For the remainder of this essay we will concentrate on scientific reasons: that probabilistic models better represent linguistic facts, and statistical techniques make it easier for us to make sense of those facts.
[…]
When Chomsky said “That’s a notion of [scientific] success that’s very novel. I don’t know of anything like it in the history of science” he apparently meant that the notion of success of “accurately modeling the world” is novel, and that the only true measure of success in the history of science is “providing insight” — of answering why things are the way they are, not just describing how they are.
[…] it seems to me that both notions have always coexisted as part of doing science. To test that, […] I then looked at all the titles and abstracts from the current issue of Science […] and did the same for the current issue of Cell […] and for the 2010 Nobel Prizes in science.
My conclusion is that 100% of these articles and awards are more about “accurately modeling the world” than they are about “providing insight,” although they all have some theoretical insight component as well.
[…]
Every probabilistic model is a superset of a deterministic model (because the deterministic model could be seen as a probabilistic model where the probabilities are restricted to be 0 or 1), so any valid criticism of probabilistic models would have to be because they are too expressive, not because they are not expressive enough.
[…]
In Syntactic Structures, Chomsky introduces a now-famous example that is another criticism of finite-state probabilistic models:
"Neither (a) ‘colorless green ideas sleep furiously’ nor (b) ‘furiously sleep ideas green colorless’, nor any of their parts, has ever occurred in the past linguistic experience of an English speaker. But (a) is grammatical, while (b) is not."
[…] a statistically-trained finite-state model can in fact distinguish between these two sentences. Pereira (2001) showed that such a model, augmented with word categories and trained by expectation maximization on newspaper text, computes that (a) is 200,000 times more probable than (b). To prove that this was not the result of Chomsky’s sentence itself sneaking into newspaper text, I repeated the experiment […] trained over the Google Book corpus from 1800 to 1954 […]
Furthermore, the statistical models are capable of delivering the judgment that both sentences are extremely improbable, when compared to, say, “Effective green products sell well.” Chomsky’s theory, being categorical, cannot make this distinction; all it can distinguish is grammatical/ungrammatical.
Another part of Chomsky’s objection is “we cannot seriously propose that a child learns the values of 109 parameters in a childhood lasting only 108 seconds.” (Note that modern models are much larger than the 109 parameters that were contemplated in the 1960s.) But of course nobody is proposing that these parameters are learned one-by-one; the right way to do learning is to set large swaths of near-zero parameters simultaneously with a smoothing or regularization procedure, and update the high-probability parameters continuously as observations comes in. Nobody is suggesting that Markov models by themselves are a serious model of human language performance. But I (and others) suggest that probabilistic, trained models are a better model of human language performance than are categorical, untrained models. And yes, it seems clear that an adult speaker of English does know billions of language facts (a speaker knows many facts about the appropriate uses of words in different contexts, such as that one says “the big game” rather than “the large game” when talking about an important football game). These facts must somehow be encoded in the brain.
It seems clear that probabilistic models are better for judging the likelihood of a sentence, or its degree of sensibility. But even if you are not interested in these factors and are only interested in the grammaticality of sentences, it still seems that probabilistic models do a better job at describing the linguistic facts. The mathematical theory of formal languages defines a language as a set of sentences. That is, every sentence is either grammatical or ungrammatical; there is no need for probability in this framework. But natural languages are not like that. A scientific theory of natural languages must account for the many phrases and sentences which leave a native speaker uncertain about their grammaticality (see Chris Manning’s article and its discussion of the phrase “as least as”), and there are phrases which some speakers find perfectly grammatical, others perfectly ungrammatical, and still others will flip-flop from one occasion to the next. Finally, there are usages which are rare in a language, but cannot be dismissed if one is concerned with actual data.
[…]
Thus it seems that grammaticality is not a categorical, deterministic judgment but rather an inherently probabilistic one. This becomes clear to anyone who spends time making observations of a corpus of actual sentences, but can remain unknown to those who think that the object of study is their own set of intuitions about grammaticality. Both observation and intuition have been used in the history of science, so neither is “novel,” but it is observation, not intuition that is the dominant model for science.
[…]
[…] I think the most relevant contribution to the current discussion is the 2001 paper by Leo Breiman (statistician, 1928–2005), Statistical Modeling: The Two Cultures. In this paper Breiman, alluding to C. P. Snow, describes two cultures:
First the data modeling culture (to which, Breiman estimates, 98% of statisticians subscribe) holds that nature can be described as a black box that has a relatively simple underlying model which maps from input variables to output variables (with perhaps some random noise thrown in). It is the job of the statistician to wisely choose an underlying model that reflects the reality of nature, and then use statistical data to estimate the parameters of the model.
Second the algorithmic modeling culture (subscribed to by 2% of statisticians and many researchers in biology, artificial intelligence, and other fields that deal with complex phenomena), which holds that nature’s black box cannot necessarily be described by a simple model. Complex algorithmic approaches (such as support vector machines or boosted decision trees or deep belief networks) are used to estimate the function that maps from input to output variables, but we have no expectation that the form of the function that emerges from this complex algorithm reflects the true underlying nature.
It seems that the algorithmic modeling culture is what Chomsky is objecting to most vigorously [because] […] algorithmic modeling describes what does happen, but it doesn’t answer the question of why.
Breiman’s article explains his objections to the first culture, data modeling. Basically, the conclusions made by data modeling are about the model, not about nature. […] The problem is, if the model does not emulate nature well, then the conclusions may be wrong. For example, linear regression is one of the most powerful tools in the statistician’s toolbox. Therefore, many analyses start out with “Assume the data are generated by a linear model…” and lack sufficient analysis of what happens if the data are not in fact generated that way. In addition, for complex problems there are usually many alternative good models, each with very similar measures of goodness of fit. How is the data modeler to choose between them? Something has to give. Breiman is inviting us to give up on the idea that we can uniquely model the true underlying form of nature’s function from inputs to outputs. Instead he asks us to be satisfied with a function that accounts for the observed data well, and generalizes to new, previously unseen data well, but may be expressed in a complex mathematical form that may bear no relation to the “true” function’s form (if such a true function even exists).
[…]
Finally, one more reason why Chomsky dislikes statistical models is that they tend to make linguistics an empirical science (a science about how people actually use language) rather than a mathematical science (an investigation of the mathematical properties of models of formal language, not of language itself). Chomsky prefers the later, as evidenced by his statement in Aspects of the Theory of Syntax (1965):
"Linguistic theory is mentalistic, since it is concerned with discovering a mental reality underlying actual behavior. Observed use of language … may provide evidence … but surely cannot constitute the subject-matter of linguistics, if this is to be a serious discipline."
I can’t imagine Laplace saying that observations of the planets cannot constitute the subject-matter of orbital mechanics, or Maxwell saying that observations of electrical charge cannot constitute the subject-matter of electromagnetism. […] So how could Chomsky say that observations of language cannot be the subject-matter of linguistics? It seems to come from his viewpoint as a Platonist and a Rationalist and perhaps a bit of a Mystic. […] But Chomsky, like Plato, has to answer where these ideal forms come from. Chomsky (1991) shows that he is happy with a Mystical answer, although he shifts vocabulary from “soul” to “biological endowment.”
"Plato’s answer was that the knowledge is ‘remembered’ from an earlier existence. The answer calls for a mechanism: perhaps the immortal soul … rephrasing Plato’s answer in terms more congenial to us today, we will say that the basic properties of cognitive systems are innate to the mind, part of human biological endowment."
[…] languages are complex, random, contingent biological processes that are subject to the whims of evolution and cultural change. What constitutes a language is not an eternal ideal form, represented by the settings of a small number of parameters, but rather is the contingent outcome of complex processes. Since they are contingent, it seems they can only be analyzed with probabilistic models. Since people have to continually understand the uncertain, ambiguous, noisy speech of others, it seems they must be using something like probabilistic reasoning. Chomsky for some reason wants to avoid this, and therefore he must declare the actual facts of language use out of bounds and declare that true linguistics only exists in the mathematical realm, where he can impose the formalism he wants. Then, to get language from this abstract, eternal, mathematical realm into the heads of people, he must fabricate a mystical facility that is exactly tuned to the eternal realm. This may be very interesting from a mathematical point of view, but it misses the point about what language is, and how it works.
The Bitter Lesson
I have a deep running soft spot for symbolic AI for many reasons:
- I love symbols, words, logic, and algebraic reasoning
- I love programming computers to do those things, with databases, backtracking, heuristics, symbolic programming, parsing, tree traversal, everything and anything else. It's just so fun and cool!
- I love systems that you can watch work and really understand.
- Symbolic AI plays to the strengths of computers — deterministic, reliable, controlled.
- I love the culture and history of that particular side of the field, stemming as it does from the Lisp hackers and the MIT AI Lab.
- I love the traditional tools and technologies of the field, like Prolog and Lisp.
Sadly, time and again symbolic AI has proven to be fundamentally the wrong approach. This famous essay outlines the empirical and technological reasons why, citing several historical precidents, that have only been confirmed even more in the intervening years. It is, truly, a bitter lesson.
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. […] We have to learn the bitter lesson that building in how we think we think does not work in the long run. The bitter lesson is based on the historical observations that
- AI researchers have often tried to build knowledge into their agents,
- this always helps in the short term, and is personally satisfying to the researcher, but
- in the long run it plateaus and even inhibits further progress, and
- breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning.
The eventual success is tinged with bitterness, and often incompletely digested, because it is success over a favored, human-centric approach.
[…]
The second general point to be learned from the bitter lesson is that the actual contents of minds are tremendously, irredeemably complex; we should stop trying to find simple ways to think about the contents of minds […] as their complexity is endless; instead we should build in only the meta-methods that can find and capture this arbitrary complexity. Essential to these methods is that they can find good approximations, but the search for them should be by our methods, not by us. We want AI agents that can discover like we can, not which contain what we have discovered. Building in our discoveries only makes it harder to see how the discovering process can be done.
See also my own thoughts on symbolism vs connectionism.
The Bitter Lesson: Rethinking How We Build AI Systems
This is a great followup to the original essay, specifically the section on how the invention of reinforcement learning only amplifies the benefits of connectionist approaches and scaling over and above symbolism and explicit rule-encoding by allowing us to still train models for specific tasks and steer them towards and away from specific behaviors using expert human knowledge, without needing to encode the specific ways to get there:
In 2025, this pattern becomes even more evident with Reinforcement Learning agents. While many companies are focused on building wrappers around generic models, essentially constraining the model to follow specific workflow paths, the real breakthrough would come from companies investing in post-training RL compute. These RL-enhanced models wouldn’t just follow predefined patterns; they are discovering entirely new ways to solve problems. […] It’s not that the wrappers are wrong; they just know one way to solve the problem. RL agents, with their freedom to explore and massive compute resources, found better ways we hadn’t even considered.
The beauty of RL agents lies in how naturally they learn. Imagine teaching someone to ride a bike - you wouldn’t give them a 50-page manual on the physics of cycling. Instead, they try, fall, adjust, and eventually master it. RL agents work similarly but at massive scale. They attempt thousands of approaches to solve a problem, receiving feedback on what worked and what didn’t. Each success strengthens certain neural pathways, each failure helps avoid dead ends.
[…]
What makes this approach powerful is that the agent isn’t limited by our preconceptions. While wrapper solutions essentially codify our current best practices, RL agents can discover entirely new best practices. They might find that combining seemingly unrelated approaches works better than our logical, step-by-step solutions. This is the bitter lesson in action - given enough compute power, learning through exploration beats hand-crafted rules every time.
The Bitter Lesson of LLM Extensions
[…] this is the bitter lesson in action[:] Giving an agent general purpose tools and trusting it to have the ability to use them to accomplish a task might very well be the winning strategy over making specialized tools for every task.
Skills are the actualization of the dream that was set out by ChatGPT Plugins: just give the model instructions and some generic tools and trust it to do the glue work in-between. But I have a hypothesis that it might actually work now because the models are actually smart enough for it to work.
What Is ChatGPT Doing … and Why Does It Work??
This is a really excellent and relatively accessible — especially with the excellent workable toy examples and illustrations which slowly build up to the full thing piece by piece — not just of how generative pretrained transformers and large language models work, but all of the concepts that build up to them, that are necessary to understand them. It also contains a sober analysis of why these models are so cool — and they are cool!! — and their very real limitations, and endorses a neurosymbolic approach similar to the one I like.
I think embeddings are one of the coolest parts of all this.
Cyc
Cyc: Obituary for the greatest monument to logical AGI
After 40 years, 30 million rules, 200 million dollars, 2000 person-years, and many promises, Cyc has failed to reach intellectual maturity, and may never will. Exacerbated by the secrecy and insularity of Cycorp, there remains no evidence of its general intelligence.
The legendary Cyc project, Douglas Lenat’s 40-year quest to build artificial general intelligence by scaling symbolic logic, has failed. Based on extensive archival research, this essay brings to light its secret history so that it may be widely known.
Let this be a bitter lesson to you.
As even Gary Marcus admits in his biggest recent paper:
Symbol-manipulation allows for the representation of abstract knowledge, but the classical approach to accumulating and representing abstract knowledge, a field known as knowledge representation, has been brutally hard work, and far from satisfactory. In the history of AI, the single largest effort to create commonsense knowledge in a machine- interpretable form, launched in 1984 by Doug Lenat, is the system known as CYC […] Thus far, the payoff has not been compelling. Relatively little has been published about CYC […] and the commercial applications seem modest, rather than overwhelming. Most people, if they know CYC at all, regard it as a failure, and few current researchers make extensive use of it. Even fewer seem inclined to try to build competing systems of comparable breadth. (Large- scale databases like Google Knowledge Graph, Freebase and YAGO focus primarily on facts rather than commonsense.)
Given how much effort CYC required, and how little impact it has had on the field as a whole, it’s hard not to be excited by Transformers like GPT- 2. When they work well, they seem almost magical, as if they automatically and almost effortlessly absorbed large swaths of common- sense knowledge of the world. For good measure,
"Transformers give the appearance of seamlessly integrating whatever knowledge they absorb with a seemingly sophisticated understanding of human language."
The contrast is striking. Whereas the knowledge representation community has struggled for decades with precise ways of stating things like the relationship between containers and their contents, and the natural language understanding community has struggled for decades with semantic parsing, Transformers like GPT2 seem as if they cut the Gordian knot—without recourse to any explicit knowledge engineering (or semantic parsing)—whatsoever.
There are, for example, no knowledge- engineered rules within GPT- 2, no specification of liquids relative to containers, nor any specification that water even is a liquid. In the examples we saw earlier
If you break a glass bottle of water, the water will probably flow out if it’s full, it will make a splashing noise.
there is no mapping from the concept H2O to the word water, nor any explicit representations of the semantics of a verb, such as break and flow.
To take another example, GPT- 2 appears to encode something about fire, as well:
a good way to light a fire is to use a lighter.
a good way to light a fire is to use a match.
Compared to Lenat’s decades-long project to hand encode human knowledge in machine interpretable form, this appears at first glance to represent both an overnight success and an astonishing savings in labor.
Types of Neuro-Symbolic AI
An excellent short guide to the different architectures that can be used to structure neuro-symbolic AI, with successful recent examples from the field's literature.
The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence
Perhaps the best general encapsulation of Gary Marcus's standpoint, and well worth reading even if to be taken with a small pinch of salt and more than a little of whatever beverage you prefer to get through the mild crankiness of it.
Two conjectures I would make are these
- We cannot construct rich cognitive models in an adequate, automated way without the triumvirate of hybrid architecture [for abstractive capabilities], rich prior knowledge [to be able to understand the world by default enough to model it], and sophisticated techniques for reasoning [to reliably be able to apply knowledge to the world without having to memorize literally everything in the world]. […]
- We cannot achieve robust intelligence without the capacity to induce and represent rich cognitive models. Reading, for example, can in part be thought a function that takes sentences as input and produces as its output (internal) cognitive models. […]
Pure co- occurrence statistics have not reliably gotten to any of this. Cyc has the capacity to represent rich cognitive models, but falls down on the job of inducing models from data, because it has no perceptual component and lacks an adequate natural language front end. Transformers, to the extent that they succeed, skip the steps of inducing and representing rich cognitive models, but do so at their peril, since the reasoning they are able to do is consequently quite limited.
ChatGPT is bullshit
Two key quotes:
[…] ChatGPT is not designed to produce true utterances; rather, it is designed to produce text which is indistinguishable from the text produced by humans. […] The basic architecture of these models reveals this: they are designed to come up with a likely continuation of a string of text. […] This is similar to standard cases of human bullshitters, who don't care whether their utterances are true […] We conclude that, even if the chatbot can be described as having intentions, it is indifferent to whether its utterances are true. It does not and cannot care about the truth of its output.
[…]
We object to the term hallucination because it carries certain misleading implications. When someone hallucinates they have a non-standard perceptual experience […] This term is inappropriate for LLMs for a variety of reasons. First, as Edwards (2023) points out, the term hallucination anthropomorphises the LLMs. […] Second, what occurs in the case of an LLM delivering false utterances is not an unusual or deviant form of the process it usually goes through (as some claim is the case in hallucinations, e.g., disjunctivists about perception). The very same process occurs when its outputs happen to be true.
[…]
Investors, policymakers, and members of the general public make decisions on how to treat these machines and how to react to them based not on a deep technical understanding of how they work, but on the often metaphorical way in which their abilities and function are communicated. Calling their mistakes 'hallucinations' isn't harmless […] As we have pointed out, they are not trying to convey information at all. They are bullshitting. Calling chatbot inaccuracies 'hallucinations' feeds in to overblown hype […] It also suggests solutions to the inaccuracy problems which might not work, and could lead to misguided efforts at Al alignment amongst specialists. It can also lead to the wrong attitude towards the machine when it gets things right: the inaccuracies show that it is bullshitting, even when it's right. Calling these inaccuracies 'bullshit' rather than 'hallucinations' isn't just more accurate (as we've argued); it's good science and technology communication in an area that sorely needs it.
For more analysis, see here.
Asymmetry of verification and verifier’s law
Asymmetry of verification is the idea that some tasks are much easier to verify than to solve. With reinforcement learning (RL) that finally works in a general sense, asymmetry of verification is becoming one of the most important ideas in AI.
[…]
Why is asymmetry of verification important? If you consider the history of deep learning, we have seen that virtually anything that can be measured can be optimized. In RL terms, ability to verify solutions is equivalent to ability to create an RL environment. Hence, we have:
Verifier’s law: The ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI.
More specifically, the ability to train AI to solve a task is proportional to whether the task has the following properties:
- Objective truth: everyone agrees what good solutions are
- Fast to verify: any given solution can be verified in a few seconds
- Scalable to verify: many solutions can be verified simultaneously
- Low noise: verification is as tightly correlated to the solution quality as possible
- Continuous reward: it’s easy to rank the goodness of many solutions for a single problem
The Model is the Product
A lot of people misunderstand what the business model of AI companies is. They think that the product is going to be whatever's built on top of the model. On the basis of this assessment, they make grand predictions about how the AI industry is failing, has no purpose, etc, or they buy into the hype of the startups serving ChatGPT wrappers, or they make wrong investments. This is an excellent analysis of why they're wrongheaded.
There were a lot of speculation over the past years about what the next cycle of AI development could be. Agents? Reasoners? Actual multimodality?
I think it's time to call it: the model is the product.
All current factors in research and market development push in this direction.
- Generalist scaling is stalling. This was the whole message behind the release of GPT-4.5: capacities are growing linearly while compute costs are on a geometric curve. Even with all the efficiency gains in training and infrastructure of the past two years, OpenAI can't deploy this giant model with a remotely affordable pricing.
- Opinionated training is working much better than expected. The combination of reinforcement learning and reasoning means that models are suddenly learning tasks. It's not machine learning, it's not base model either, it's a secret third thing. It's even tiny models getting suddenly scary good at math. It's coding model no longer just generating code but managing an entire code base by themselves. It's Claude playing Pokemon with very poor contextual information and no dedicated training.
- Inference cost are in free fall. The recent optimizations from DeepSeek means that all the available GPUs could cover a demand of 10k tokens per day from a frontier model for… the entire earth population. There is nowhere this level of demand. The economics of selling tokens does not work anymore for model providers: they have to move higher up in the value chain.
This is also an uncomfortable direction. All investors have been betting on the application layer. In the next stage of AI evolution, the application layer is likely to be the first to be automated and disrupted.
Model Adoption Is Fragmenting
I think this is interesting news, economically, for the AI bubble:
Three main insights emerge from this dataset:
- Adoption is diversifying, not consolidating. Newer models are not always better for every workflow.
- Behavioral divergence is measurable. Sonnet 4.5 reasons more deeply, while 4.0 acts more frequently.
- System costs are shifting. Reasoning intensity and cache utilization are now central performance metrics.
The story here is not about one model surpassing others but about each developing its own niche. As capabilities expand, behaviors diverge. The industry may be entering a stage where functional specialization replaces the race for a single “best” model—much like how databases evolved into SQL, NoSQL, and time-series systems optimized for different workloads. The same dynamic is beginning to appear in AI: success depends less on overall strength and more on the right cognitive style for the job.
The reason I find this interesting is that it illustrates two things.
First, we are reaching no longer at a stage in the development of AI where you can make a model that is universally and qualitatively better at everything it might be used for, iteratively. Instead, we are now in a stage where — while we are still achieving decent advantages along different parts of the frontier — we have to make tradeoffs between the different capabilities, performance aspects, and behavioral features a model might have; to advance a model along one part of the frontier might leave it the same, or even a little worse, on other parts of the frontier. This isn't something you really see when you're in a regime where everything can be improved limitlessly; this is something you see in a phase of technological development where you're hitting the limits of your basic techniques, and improvement is a limited quantity — thus, improve in one area, and you have to pay costs in other areas. Essentially, we've begun to hit an inflection point in the sigmoid curve of technological advancement.
Second, and as a corollary, the fact that you can have models that are genuinely better than average at some things and worse at others, with meaningful and interesting trade-offs, and you can't just have all that come out in the wash with a new version bump, and where one model being "better" in terms of total score on various benchmarks or how many benchmarks it's able to complete doesn't really matter too much in comparison to other characteristics, means that we're entering a situation where it makes sense to have a diverse market of different competitors.
I think this seriously unsettles a lot of the thinking around the AI industry/bubble lately, both pro and con.
This is a problem for the core bet that most AI companies seem to be making: that there can be one obvious "winner" in this market that will have some sort of natural monopoly, whoever that is will be the one that scales the most ruthlessly, and once you become that central single winner, you can recoup all your profits because you'll be totally unopposed. If that's not the case — if, independent of whether or not we are going to get LLMs that are significantly better at various things than they are today, there are these meaningful trade-offs in model capability and meaningful differences in behavior that matter more than raw capability anyway — then it's not obvious that there even can be a clear "winner" to the race. It seems likely there will be a multiplicity of different models; you can't just own the entire market, as all of these companies seem to want to do. And if that's not the case, then all that money they're spending recklessly, dangerously, terrifyingly scaling out their compute infrastructure and their models, is going to be for nothing. Maybe they'll be able to pay back their loans; maybe they won't; but it'll still be a massive waste of money that will be difficult to overcome.
It also undercuts this logic that we're on the cusp of AGI, and that we can keep scaling LLMs to get there. This will come as no surprise to anyone who wasn't religiously bought into the AGI hype to begin with, but we're at the point of diminishing returns on all dimensions of the spider graph of a model's capabilities, this suggests we've hit an inflection point, which shows that you can't get the sort of eternal, exponential growth in model capabilities that AI hypesters want, and that also puts a big question mark after a lot of the serious claims, bets, and promises these AI companies have made.
And to be clear, these are all problems even if generative AI has an ecnomically viable, profitable market, and even if token inference is profitable (as I believe they are).
At the same time, I think this also undercuts some of the key components of the critiques of the AI industry as well: namely, first the idea that AI companies "have no moat," and, second, the idea that AI companies need to continue funding new tranining runs and scaling up forever to remain profitable.
A lot of the points that Ed Zitron, Cory Doctorow, and Gary Marcus depend on this first idea — that AI companies can't really have a moat because all of their models are trained on the same data and perform essentially the same task: token completion and language modeling. Therefore, there's no real differentiating factor, and thus no reason to choose any given model over any other, creating a perfectly frictionless market for consumers but one where competition is basically impossible for producers. They speculate that, given this, even if the AI market as a whole — the concept of generative artificial intelligence — has economic value, nobody is going to be able to capture that value: as soon as any player enters the market, other competitors will just enter, people will switch to whoever's cheapest/free, and this will drive prices down to the point where nobody can be profitable. The whole market would become one of those classic market failures where there might be use-value to be found, but it's not something that a free market can capture, and so the industry will die; even if it doesn't die, it won't be a very profitable market — certainly not profitable enough to pay back all of their loans — because of this lack of differentiating factors.
This already has problems, because if there's a fixed cost to running AI inference, as well as an up front cost to training AIs, no company is, in the long run, going to sell below the price needed to pay back the inference costs plus the up front cost plus get some profit on the top, and so there just won't be any companies offering models for free or cheaper than cost-price in the long run, thus there wouldn't be any competitor for customers to switch to with that frictionless switching that would have those free or below cost prices, thus meaning there'd be no way to push prices down below what cost requires. That's just how price works. Now, you could argue that if users were charged those actual prices, no one would pay, but that's a completely separate argument (and one that I don't buy at all).
However, if this new data is true — and anecdotally, from what I've seen on Reddit, Hacker News, and Lobsters, it is — then it indicates there's an even bigger problem for this critique of the AI industry: it is actually possible to differentiate your models from other models and thus build a moat. If it's all tradeoffs from here on out in terms of performance, behavior, and capability profile, then that means people will prefer different models for different tasks or workflows, and companies can specialize. This data also shows that, to a degree, it doesn't even matter if your model is quantitatively better at completing all the benchmarks — at capabilities in the abstract — if it doesn't match the behavior and performance profile people are looking for for a certain task and workflow. Which, again, means not only that there can be a moat, and that monopolies probably won't be possible, but also that smaller players can meaningfully compete!
Ultimately, what this comes down to is that reinforcement learning is where all the value-add comes from at this point in a model's development. Everyone has the same basic technology, everyone has the same basic hardware, and everyone has basically the exact same data because everyone is just using all of the data that exists. So there's not really space for differentiation there. But you can make a massive difference in how a model behaves and what it's good and bad at through supervised fine-tuning, instruction fine-tuning, reinforcement learning with objective metrics (for code, math, etc.), and reinforcement learning with human feedback. These processes can produce models that are completely different, not just in terms of writing personality, but as you see in the data they show: the tasks people tend to use them for, tool-calling frequency, and how verbose they are before they call tools or in explaining things, and so on.
This goes back to the thesis of "the model is the product." I don't think that article's idea of training models for specific tasks is precisely what's going to happen. But I do think most of the value-add for models is going to be in the specific reinforcement learning they get in the post-training process.
TODO Introducing Nested Learning: A new ML paradigm for continual learning
Over the last decades, developing more powerful neural architectures and simultaneously designing optimization algorithms to effectively train them have been the core of research efforts to enhance the capability of machine learning models. Despite the recent progresses, particularly in developing Language Models (LMs), there are fundamental challenges and unanswered questions about how such models can continually learn/memorize, self-improved, and find “effective solutions,”. In this paper, we present a new learning paradigm, called Nested Learning (NL), that coherently represents a model with a set of nested, multi-level, and/or parallel optimization problems, each of which with its own “context flow”. NL reveals that existing deep learning methods learns from data through compressing their own context flow, and explain how in-context learning emerges in large models. NL suggests a path (a new dimension to deep learning) to design more expressive learning algorithms with more “levels”, resulting in higher-order in-context learning abilities. In addition to its neuroscientifically plausible and mathematically white-box nature, we advocate for its importance by presenting three core contributions: (1) Deep Optimizers: Based on NL, we show that well-known gradient-based optimizers (e.g., Adam, SGD with Momentum, etc.) are in fact associative memory modules that aim to compress the gradients with gradient descent. Building on this insight, we present a set of more expressive optimizers with deep memory and/or more powerful learning rules; (2) Self-Modifying Titans: Taking advantage of NL’s insights on learning algorithms, we present a novel sequence model that learns how to modify itself by learning its own update algorithm; and (3) Continuum Memory System: We present a new formulation for memory system that generalizes the traditional viewpoint of “long-term/short-term memory”. Combining our self-modifying sequence model with the continuum memory system, we present a learning module, called HOPE, showing promising results in language modeling, continual learning, and long-context reasoning tasks.
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
The reward is the source of the training signal, which decides the optimization direction of RL. To train DeepSeek-R1-Zero, we adopt a rule-based reward system that mainly consists of two types of rewards:
- Accuracy rewards: The accuracy reward model evaluates whether the response is correct. For example, in the case of math problems with deterministic results, the model is required to provide the final answer in a specified format (e.g., within a box), enabling reliable rule-based verification of correctness. Similarly, for LeetCode problems, a compiler can be used to generate feedback based on predefined test cases.
- Format rewards: In addition to the accuracy reward model, we employ a format reward model that enforces the model to put its thinking process between ‘<think>’ and ‘</think>’ tags.
We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline.
[…]
The self-evolution process of DeepSeek-R1-Zero is a fascinating demonstration of how RL can drive a model to improve its reasoning capabilities autonomously. By initiating RL directly from the base model, we can closely monitor the model’s progression without the influence of the supervised fine-tuning stage. This approach provides a clear view of how the model evolves over time, particularly in terms of its ability to handle complex reasoning tasks.
As depicted in Figure 3, the thinking time of DeepSeek-R1-Zero shows consistent improvement throughout the training process. This improvement is not the result of external adjustments but rather an intrinsic development within the model. DeepSeek-R1-Zero naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time computation. […]
One of the most remarkable aspects of this self-evolution is the emergence of sophisticated behaviors as the test-time computation increases. Behaviors such as reflection—where the model revisits and reevaluates its previous steps—and the exploration of alternative approaches to problem-solving arise spontaneously. These behaviors are not explicitly programmed but instead emerge as a result of the model’s interaction with the reinforcement learning environment. This spontaneous development significantly enhances DeepSeek-R1-Zero’s reasoning capabilities, enabling it to tackle more challenging tasks with greater efficiency and accuracy.
[…]
A particularly intriguing phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of an “aha moment”. This moment, as illustrated in Table 3, occurs in an intermediate version of the model. During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach. This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes.
This moment is not only an “aha moment” for the model but also for the researchers observing its behavior. It underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. The “aha moment” serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems, paving the way for more autonomous and adaptive models in the future.
Kimi K2 Technical Report
Building on these advances and inspired by ACEBench [7]’s comprehensive data synthesis framework, we developed a pipeline that simulates real-world tool-use scenarios at scale, enabling the generation of tens of thousands of diverse and high-quality training examples. […]
Domain Evolution and Tool Generation. We construct a comprehensive tool repository through two complementary approaches. First, we directly fetch 3000+ real MCP (Model Context Protocol) tools from GitHub repositories, leveraging existing high-quality tool specs. Second, we systematically evolve [82] synthetic tools through a hierarchical domain generation process: we begin with key categories (e.g., financial trading, software applications, robot control), then evolve multiple specific application domains within each category. Specialized tools are then synthesized for each domain, with clear interfaces, descriptions, and operational semantics. This evolution process produces over 20,000 synthetic tools. Figure 9 visualizes the diversity of our tool collection through t-SNE embeddings, demonstrating that both MCP and synthetic tools cover complementary regions of the tool space.
Agent Diversification. We generate thousands of distinct agents by synthesizing various system prompts and equipping them with different combinations of tools from our repository. This creates a diverse population of agents with varied capabilities, areas of expertise, and behavioral patterns, ensuring a broad coverage of potential use cases.
Rubric-Based Task Generation. For each agent configuration, we generate tasks that range from simple to complex operations. Each task is paired with an explicit rubric that specifies success criteria, expected tool-use patterns, and evaluation checkpoints. This rubric-based approach ensures a consistent and objective evaluation of agent performance.
Multi-turn Trajectory Generation. We simulate realistic tool-use scenarios through several components:
- User Simulation: LLM-generated user personas with distinct communication styles and preferences engage in multi-turn dialogues with agents, creating naturalistic interaction patterns.
- Tool Execution Environment: A sophisticated tool simulator (functionally equivalent to a world model) executes tool calls and provides realistic feedback. The simulator maintains and updates state after each tool execution, enabling complex multi-step interactions with persistent effects. It introduces controlled stochasticity to produce varied outcomes including successes, partial failures, and edge cases.
Quality Evaluation and Filtering. An LLM-based judge evaluates each trajectory against the task rubrics. Only trajectories that meet the success criteria are retained for training, ensuring high-quality data while allowing natural variation in task-completion strategies.
Hybrid Approach with Real Execution Environments. While simulation provides scalability, we acknowledge the inherent limitation of simulation fidelity. To address this, we complement our simulated environments with real execution sandboxes for scenarios where authenticity is crucial, particularly in coding and software engineering tasks. These real sandboxes execute actual code, interact with genuine development environments, and provide ground-truth feedback through objective metrics such as test suite pass rates. This combination ensures that our models learn from both the diversity of simulated scenarios and the authenticity of real executions, significantly strengthening practical agent capabilities.
By leveraging this hybrid pipeline that combines scalable simulation with targeted real-world execution, we generate diverse, high-quality tool-use demonstrations that balance coverage and authenticity.
Reinforcement learning (RL) is believed to have better token efficiency and generalization than SFT. Based on the work of K1.5 [36], we continue to scale RL in both task diversity and training FLOPs in K2. To support this, we develop a Gym-like extensible framework that facilitates RL across a wide range of scenarios. We extend the framework with a large number of tasks with verifiable rewards. […]
3.2.1 erifiable Rewards Gym
Math, STEM and Logical Tasks. For math, stem and logical reasoning domains, our RL data preparation follows two key principles, diverse coverage and moderate difficulty.
- Diverse Coverage. For math and stem tasks, we collect high-quality QA pairs using a combination of expert annotations, internal QA extraction pipelines, and open datasets [42, 52]. During the collection process, we leverage a tagging system to deliberately increase coverage of under-covered domains. For logical tasks, our dataset comprises a variety of formats, including structured data tasks (e.g., multi-hop tabular reasoning, cross-table aggregation) and logic puzzles (e.g., the 24-game, Sudoku, riddles, cryptarithms, and Morse-code decoding).
- Moderate Difficulty. The RL prompt-set should be neither too easy nor too hard, both of which may produce little signal and reduce learning efficiency. We assess the difficulty of each problem using the SFT model’s pass@k accuracy and select only problems with moderate difficulty.
Complex Instruction Following. Effective instruction following requires not only understanding explicit constraints but also navigating implicit requirements, handling edge cases, and maintaining consistency over extended dialogues. We address these challenges through a hybrid verification framework that combines automated verification with adversarial detection, coupled with a scalable curriculum generation pipeline. Our approach employs a dual-path system to ensure both precision and robustness:
- Hybrid Rule Verification. We implement two verification mechanisms: (1) deterministic evaluation via code interpreters for instructions with verifiable outputs (e.g., length, style constraints), and (2) LLM-as-judge evaluation for instructions requiring nuanced understanding of constraints. To address potential adversarial behaviors where models might claim instruction fulfillment without actual compliance, we incorporate an additional hack-check layer that specifically detects such deceptive claims.
- Multi-Source Instruction Generation. To construct our training data, we employ three distinct generation strategies to ensure comprehensive coverage: (1) expert-crafted complex conditional prompts and rubrics developed by our data team (2) agentic instruction augmentation inspired by AutoIF [13], and (3) a fine-tuned model specialized for generating additional instructions that probe specific failure modes or edge cases. This multipronged approach ensures both breadth and depth in instruction coverage.
Faithfulness. Faithfulness is essential for an agentic model operating in scenarios such as multi-turn tool use, self-generated reasoning chains, and open-environment interactions. Inspired by the evaluation framework from FACTS Grounding [31], we train a sentence-level faithfulness judge model to perform automated verification. The judge is effective in detecting sentences that make a factual claim without supporting evidence in context. It serves as a reward model to enhance overall faithfulness performance.
Coding & Software Engineering. To enhance our capability in tackling competition-level programming problems, we gather problems and their judges from both open-source datasets [28, 83] and synthetic sources. To ensure the diversity of the synthetic data and the correctness of reward signals, we incorporate high-quality human-written unit tests retrieved from pre-training data. For software engineering tasks, we collect a vast amount of pull requests and issues from GitHub to build software development environment that consists of user prompts/issues and executable unit tests. This environment was built on a robust sandbox infrastructure, powered by Kubernetes for scalability and security. It supports over 10,000 concurrent sandbox instances with stable performance, making it ideal for both competitive coding and software engineering tasks.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Reasoning RL focuses on enhancing a model’s capabilities in domains that demand logical deduction, structured problem-solving, and verifiable accuracy. This includes critical areas such as mathematics, code generation, and scientific reasoning. A defining characteristic of these tasks is the high precision of their reward signals, as correctness can often be determined programmatically or with objective clarity. Mastery in these areas is not only crucial for advancing the raw intelligence of models but also serves as a fundamental building block for more complex, multi-step agentic behaviors. […]
Difficulty-based Curriculum Learning. During reinforcement learning, the model’s proficiency evolves, creating a mismatch with static training data. In the later stages, as the model becomes more capable, overly simple data can lead to rollouts where all rewards are 1s. Conversely, in the early stages, excessively difficult data often results in batches where all rewards are 0s. In both scenarios, the lack of reward variance provides no useful gradient signal, severely hindering training efficiency. To address this challenge, we employ a two-stage difficulty-based curriculum for RL. The effectiveness of this and other strategies discussed below is validated through controlled experiments on a smaller model, which allows for rapid iteration and precise ablation studies.
[…]
Reinforcement Learning from Human Feedback (RLHF) helps language models follow human instructions more faithfully. Applying RL to math and programming contests has further uncovered strong reasoning abilities and favorable scaling behavior on tasks whose outcomes can be objectively verified. Building on these insights, we focus on agentic settings—specifically web-search and code-generation agents—where every action or answer can be automatically checked. This built-in verifiability supplies dense, reliable rewards, enabling us to scale RL training more effectively.
For web- search tasks and open - domain information seeking, we develop a data - synthesis pipeline that yields demanding question–answer pairs requiring multi -step reasoning across multiple web sources. This corpus is designed to sharpen GLM’s ability to uncover elusive, interwoven facts on the internet. Dataset construction blends two approaches: (1) an automated pipeline powered by multi- hop reasoning over knowledge graphs, and (2) human- in- the -loop extraction and selective obfuscation of content from several web pages to prepare reinforcement-learning training signals.
For software-engineering tasks, we curate an extensive collection of GitHub pull requests and issues to create a realistic software- development benchmark comprising user prompts and executable unit tests. All evaluations run inside a hardened sandbox with a distributed system, which provides both horizontal scalability and strong isolation guarantees.
Scaling Test-time Compute via Interaction. Turns For agent tasks, we observe significant perfor- mance gains given increasing interaction turns with the environment. Compared to test-time scaling in reasoning models, which scales output tokens, agent tasks make use of test-time compute by continuously interacting with the environment, e.g., searching high and low for hard-to-find web information or writing test cases for self-verification and self-correction for coding tasks. Figure 8 shows that with varying browsing effort, accuracy scales smoothly with test-time compute.
*
TODO A General Language Assistant as a Laboratory for Alignment
This is the paper that first came up with the idea of presenting language models with a script to complete as a way of getting them to act like chatbot assistants. The hyperstition that prefigured everything.
Given the broad capabilities of large language models, it should be possible to work towards a general-purpose, text-based assistant that is aligned with human values, meaning that it is helpful, honest, and harmless. As an initial foray in this direction we study simple baseline techniques and evaluations, such as prompting. We find that the benefits from modest interventions increase with model size, generalize to a variety of alignment evaluations, and do not compromise the performance of large models. Next we investigate scaling trends for several training objectives relevant to alignment, comparing imitation learning, binary discrimination, and ranked preference modeling. We find that ranked preference modeling performs much better than imitation learning, and often scales more favorably with model size. In contrast, binary discrimination typically performs and scales very similarly to imitation learning. Finally we study a ‘preference model pre-training’ stage of training, with the goal of improving sample efficiency when finetuning on human preferences.
TODO Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
TODO Adaptive Mixtures of Local Experts
We present a new supervised learning procedure for systems composed of many separate networks, each of which learns to handle a subset of the complete set of training cases. The new procedure can be viewed either as a modular version of a multilayer supervised network, or as an associative version of competitive learning. It therefore provides a new link between these two apparently different approaches. We demonstrate that the learning procedure divides up a vowel discrimination task into appropriate subtasks, each of which can be solved by a very simple expert network.
TODO Calculus on Computational Graphs: Backpropagation
Backpropagation is the key algorithm that makes training deep models computationally tractable. For modern neural networks, it can make training with gradient descent as much as ten million times faster, relative to a naive implementation. That’s the difference between a model taking a week to train and taking 200,000 years.
Beyond its use in deep learning, backpropagation is a powerful computational tool in many other areas, ranging from weather forecasting to analyzing numerical stability – it just goes by different names. In fact, the algorithm has been reinvented at least dozens of times in different fields (see Griewank (2010)). The general, application independent, name is “reverse-mode differentiation.”
Fundamentally, it’s a technique for calculating derivatives quickly. And it’s an essential trick to have in your bag, not only in deep learning, but in a wide variety of numerical computing situations.
TODO Continuous Thought Machines
Biological brains demonstrate complex neural activity, where neural dynamics are critical to how brains process information. Most artificial neural networks ignore the complexity of individual neurons . We challenge that paradigm. By incorporating neuron-level processing and synchronization, we reintroduce neural timing as a foundational element. We present the Continuous Thought Machine (CTM), a model designed to leverage neural dynamics as its core representation. The CTM has two innovations: (1) neuron-level temporal processing, where each neuron uses unique weight parameters to process incoming histories; and (2) neural synchronization as a latent representation. The CTM aims to strike a balance between neuron abstractions and biological realism. It operates at a level of abstraction that effectively captures essential temporal dynamics while remaining computationally tractable. We demonstrate the CTM’s performance and versatility across a range of tasks, including solving 2D mazes, ImageNet-1K classification, parity computation, and more. Beyond displaying rich internal representations and offering a natural avenue for interpretation owing to its internal process, the CTM is able to perform tasks that require complex sequential reasoning. The CTM can also leverage adaptive compute, where it can stop earlier for simpler tasks, or keep computing when faced with more challenging instances. The goal of this work is to share the CTM and its associated innovations, rather than pushing for new state-of-the-art results. To that end, we believe the CTM represents a significant step toward developing more biologically plausible and powerful artificial intelligence systems. We provide an accompanying interactive online demonstration and an extended technical report.
TODO Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
We explore how generating a chain of thought—a series of intermediate reasoning steps—significantly improves the ability of large language models to perform complex reasoning. In particular, we show how such reasoning abilities emerge naturally in sufficiently large language models via a simple method called chain-of-thought prompting, where a few chain of thought demonstrations are provided as exemplars in prompting.
Experiments on three large language models show that chain-of-thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks. The empirical gains can be striking. For instance, prompting a PaLM 540B with just eight chain-of-thought exemplars achieves state-of-the-art accuracy on the GSM8K benchmark of math word problems, surpassing even finetuned GPT-3 with a verifier.
[Image: A diagram comparing “Standard Prompting” with “Chain-of-Thought Prompting”. Under Standard Prompting, the model is given a question and a direct answer, and it produces an incorrect answer for a new question. Under Chain-of-Thought Prompting, the model is given a question with a step-by-step reasoning process (the chain of thought) leading to the answer. For the new question, the model then generates its own chain of thought, leading to the correct answer.]
Figure 1: Chain-of-thought prompting enables large language models to tackle complex arithmetic, commonsense, and symbolic reasoning tasks. Chain-of-thought reasoning processes are highlighted.
TODO Solving a Million-Step LLM Task with Zero Errors
LLMs have achieved remarkable breakthroughs in reasoning, insights, and tool use, but chaining these abilities into extended processes at the scale of those routinely executed by humans, organizations, and societies has remained out of reach. The models have a persistent error rate that prevents scale-up: for instance, recent experiments in the Towers of Hanoi benchmark domain showed that the process inevitably becomes derailed after at most a few hundred steps. Thus, although LLM research is often still benchmarked on tasks with relatively few dependent logical steps, there is increasing attention on the ability (or inability) of LLMs to perform long range tasks. This paper describes MAKER, the first system that successfully solves a task with over one million LLM steps with zero errors, and, in principle, scales far beyond this level. The approach relies on an extreme decomposition of a task into subtasks, each of which can be tackled by focused microagents. The high level of modularity resulting from the decomposition allows error correction to be applied at each step through an efficient multi-agent voting scheme. This combination of extreme decomposition and error correction makes scaling possible. Thus, the results suggest that instead of relying on continual improvement of current LLMs, massively decomposed agentic processes (MDAPs) may provide a way to efficiently solve problems at the level of organizations and societies.
TODO REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
While large language models (LLMs) have demonstrated impressive performance across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-thought prompting) and acting (e.g. action plan generation) have primarily been studied as separate topics. In this paper, we explore the use of LLMs to generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two: reasoning traces help the model induce, track, and update action plans as well as handle exceptions, while actions allow it to interface with and gather additional information from external sources such as knowledge bases or environments. We apply our approach, named ReAct, to a diverse set of language and decision making tasks and demonstrate its effectiveness over state-of-the-art baselines in addition to improved human interpretability and trustworthiness. Concretely, on question answering (HotpotQA) and fact verification (Fever), ReAct overcomes prevalent issues of hallucination and error propagation in chain-of-thought reasoning by interacting with a simple Wikipedia API, and generating human-like task-solving trajectories that are more interpretable than baselines without reasoning traces. Furthermore, on two interactive decision making benchmarks (ALFWorld and WebShop), ReAct outperforms imitation and reinforcement learning methods by an absolute success rate of 34% and 10% respectively, while being prompted with only one or two in-context examples.
How o3 and Grok 4 Accidentally Vindicated Neurosymbolic AI
The essential premise of neurosymbolic AI is this: the two most common approaches to AI, neural networks and classical symbolic AI, have complementary strengths and weaknesses. Neural networks are good at learning but weak at generalization; symbolic systems are good at generalization, but not at learning. […]
First among the big players to look more broadly was Google DeepMind, which wisely has not taken Hinton’s dogma overly seriously. AlphaFold, AlphaProof, and AlphaGeometry are all successful neurosymbolic models. We would likely have more of such innovation already, if Hinton had not so insistently shaped the modern landscape in such a narrow-minded way.
[…]
Three years later, the pure scaling of pretraining data (and compute, which is to say more and more GPUs) simply hasn’t worked. The specific obstacles that I dwelled on, with respect to hallucinations, misalignment and reasoning errors, have not been overcome.
[…]
What has worked—to some degree—is importing some of the ideas from neurosymbolic AI, including using purely symbolic algorithms as a direct part of the workflow.
OpenAI quietly began doing this to some degree in 2023 with a system called “code interpreter”, in which LLMs (themselves neural networks) call (purely symbolic) Python interpreters. This is literally “putting programs inside”; exactly what Hinton said was a huge mistake. And they are innately building in that capacity, rather than learning it.
[…]
As leading machine learning expert Francois Chollet explained last year on X, such systems are manifestly neurosymbolic,
“Obviously combining a code interpreter (which is a symbolic system of enormous complexity) with an LLM is neurosymbolic. AlphaGo was neurosymbolic as well. These are universally accepted definitions.”
Recent “reasoning” models borrow even more from classic symbolic approaches, such as techniques like search and conditionally iterating through multiple solutions, and aggregating the results, techniques that traditional networks had long eschewed, in favor of a single feed-forward pass through a neural net.
From what I can tell, most modern models also make heavy use of data augmentation that involves (inter alia) running systems of symbolic rules and training on their outputs, a far cry from the original notion of training on naturalistically-observed data and then inducing whatever needed to be learned.
[…]
Both informal experimentation and a number of recent quantitative results make it abundantly clear that current generative AI systems perform better when they avail themselves of symbolic tools. (Again, per Chollet, when you combine an LLM with a symbolic tool, you have a neurosymbolic system.)
The much-discussed Apple paper was one hint: the authors explicitly forced LLMs to do various tasks, such as Tower of Hanoi, without recourse to using code (symbolic by definition), and it’s under that scenario that they found breakdowns, such as failures on Hanoi with 8 rings.
Another research group, explicitly responding to the Apple paper, showed how you could get much better performance on problems like Hanoi by having models like o3 explicitly invoke code.
[…]
The results that seal the deal came a few nights ago, at the launch of Grok 4, perhaps the largest and most expensive model in history. (Elon Musk claims it used 100 times the compute of Grok 2.)
This graph (of a challenging benchmark known as Humanity’s Last Exam) is without question one of the most vindicating things I have ever seen:
Why? Two things can be seen.
First, the lower set of data (yellow dots) represent a strong test of the pure scaling hypothesis. Although the units on the X axis aren’t made clear, it’s quite clear that pure scaling of training data and computer is reaching a point of diminishing returns, a long way from peak possible performance. Contrary to lots of talk from previous years, increasing compute alone is not driving some miraculous exponential explosion into superintelligence.
Second, adding symbolic tools (orange dots) dramatically improves performance.
Animals vs Ghosts
As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea is sufficiently "bitter lesson pilled" (meaning arranged so that it benefits from added computation for free) as a proxy for whether it's going to work or worth even pursuing. The underlying assumption being that LLMs are of course highly "bitter lesson pilled" […] So it's amusing to see that Sutton, the author of the post, is not so sure that LLMs are "bitter lesson pilled" at all. They are trained on giant datasets of fundamentally human data, which is both 1) human generated and 2) finite. What do you do when you run out? How do you prevent a human bias? So there you have it, bitter lesson pilled LLM researchers taken down by the author of the bitter lesson - rough!
I also think that his criticism of LLMs as not bitter lesson pilled is not inadequate. […] We do not in fact have an actual, single, clean, actually bitter lesson pilled, "turn the crank" algorithm that you could unleash upon the world and see it learn automatically from experience alone.
Does such an algorithm even exist? […] Two "example proofs" are commonly offered to argue that such a thing is possible. The first example is the success of AlphaZero learning to play Go completely from scratch with no human supervision whatsoever. But the game of Go is clearly such a simple, closed, environment that it's difficult to see the analogous formulation in the messiness of reality. […] The second example is that of animals, like squirrels. And here, personally, I am also quite hesitant whether it's appropriate […] Animal brains are nowhere near the blank slate they appear to be at birth. First, a lot of what is commonly attributed to "learning" is imo a lot more "maturation". And second, even that which clearly is "learning" and not maturation is a lot more "finetuning" on top of something clearly powerful and preexisting. Example. A baby zebra is born and within a few dozen minutes it can run around the savannah and follow its mother. This is a highly complex sensory-motor task and there is no way in my mind that this is achieved from scratch, tabula rasa. […] If the baby zebra spasmed its muscles around at random as a reinforcement learning policy would have you do at initialization, it wouldn't get very far at all. Similarly, our AIs now also have neural networks with billions of parameters. These parameters need their own rich, high information density supervision signal. We are not going to re-run evolution. But we do have mountains of internet documents. Yes it is basically supervised learning that is ~absent in the animal kingdom. But it is a way to practically gather enough soft constraints over billions of parameters, to try to get to a point where you're not starting from scratch.
[…]
Stated plainly, today's frontier LLM research is not about building animals. It is about summoning ghosts. You can think of ghosts as a fundamentally different kind of point in the space of possible intelligences. They are muddled by humanity. Thoroughly engineered by it. They are these imperfect replicas, a kind of statistical distillation of humanity's documents with some sprinkle on top. They are not platonically bitter lesson pilled, but they are perhaps "practically" bitter lesson pilled, at least compared to a lot of what came before.
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs
Recent advancements in long chain-of-thought (CoT) reasoning, particularly through the Group Relative Policy Optimization algorithm used by DeepSeek-R1, have led to significant interest in the potential of Reinforcement Learning with Verifiable Rewards (RLVR) for Large Language Models (LLMs). While RLVR promises to improve reasoning by allowing models to learn from free exploration, there remains debate over whether it truly enhances reasoning abilities or simply boosts sampling efficiency. This paper systematically investigates the impact of RLVR on LLM reasoning. We revisit Pass@K experiments and demonstrate that RLVR can extend the reasoning boundary for both mathematical and coding tasks. This is supported by our introduction of a novel evaluation metric, CoT-Pass@K, which captures reasoning success by accounting for both the final answer and intermediate reasoning steps. Furthermore, we present a theoretical framework explaining RLVR’s incentive mechanism, demonstrating how it can encourage correct reasoning even when rewards are based solely on answer correctness. Our analysis of RLVR’s training dynamics reveals that it incentivizes correct reasoning early in the process, with substantial improvements in reasoning quality confirmed through extensive evaluations. These findings provide strong evidence of RLVR’s potential to enhance LLM reasoning, offering valuable insights into its mechanisms and performance improvements.
TODO The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
The emergence of agentic reinforcement learning (Agentic RL) marks a paradigm shift from conventional reinforcement learning applied to large language models (LLM RL), reframing LLMs from passive sequence generators into autonomous, decision-making agents embedded in complex, dynamic worlds. This survey formalizes this conceptual shift by contrasting the degenerate single-step Markov Decision Processes (MDPs) of LLM-RL with the partially observable, temporally extended partially observable Markov decision process (POMDP) that define Agentic RL. Building on this foundation, we propose a comprehensive twofold taxonomy: one organized around core agentic capabilities, including planning, tool use, memory, reasoning, self-improvement, and perception, and the other around their applications across diverse task domains. Central to our thesis is that reinforcement learning serves as the critical mechanism for transforming these capabilities from static, heuristic modules into adaptive, robust agentic behavior. To support and accelerate future research, we consolidate the landscape of open-source environments, benchmarks, and frameworks into a practical compendium. By synthesizing over five hundred recent works, this survey charts the contours of this rapidly evolving field and highlights the opportunities and challenges that will shape the development of scalable, general-purpose AI agents.

This study pretty conclusively shows what I've been saying for awhile now, that since agentic RL gives models concrete tasks and tools to achieve those tasks in simulated environments, lets them attempt them, then rewards or punishes them based on that, possibly with verifiable rewards, pretraining to predict the next likely token to create human-like text becomes just the model's basic prior, to allow it to "coherently speak" so to speak, and the true rewarded task of the final model becomes accurate and successful problem-solving, and that this is basically the status quo for most modern advanced models now. LLMs are no longer spicy autocomplete.
TODO Finetuned Language Models Are Zero-Shot Learners
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning—finetuning language models on a collection of datasets described via instructions—substantially improves zero-shot performance on unseen tasks.
We take a 137B parameter pretrained language model and instruction tune it on over 60 NLP datasets verbalized via natural language instruction templates. We evaluate this instruction-tuned model, which we call FLAN, on unseen task types. FLAN substantially improves the performance of its unmodified counterpart and surpasses zero-shot 175B GPT-3 on 20 of 25 datasets that we evaluate. FLAN even outperforms few-shot GPT-3 by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. Ablation studies reveal that number of finetuning datasets, model scale, and natural language instructions are key to the success of instruction tuning.
Economics
Are OpenAI and Anthropic Really Losing Money on Inference?
Some have not found "LLMs are cheap" convincing, which is fair. Here is my response to the most common objections:
Nothing on infra costs, hardware throughput + capacity (accounting for hidden tokens) & depreciation
That's because it's coming at things from the other end: since we can't be sure exactly what companies are doing, we're just going to look at the actual market incentives and pricing available and try to work backwards from there. And to be fair, it also cites, for instance, deepseek's paper where they talk about what their power foot margins are on inference.
just a blind faith that pricing by providers "covers all costs and more"
It's not blind faith. I think they make a really good argument for why the pricing by providers almost certainly does cover all the costs and more. Again, including citing white papers by some of those providers.
Naive estimate of 1000 tokens per search using some simplistic queries, exactly the kind of usage you don't need or want an LLM for.
Those token estimates were for comparing to search pricing to establish whether LLMs are expensive for users, compared to other similar things — so obviously they wanted to choose something where the domain is similar, and the closest available analogy is search; so they compared AI to search, with its behavior in a similar regieme. Of course people use LLMs for much more than search, but that's amost a point in favor of its profitability, and I think in a lot of those use-cases — especially code, where prompt caching and very high intput token to output token ratios make model usage very efficient — model usage isn't going to be that much more expensive such that it'd change the range of prices people are looking at.
Doesn't account at all for chain-of-thought (hidden tokens) that count as output tokens by the providers but are not present in the output (surprise).
Most open-source providers provide thinking tokens in the output. Just separated by some tokens so that UI and agent software can separate it out if they want to. I believe the number of thinking tokens that Cn be known as well. For instance, the recent Augment Code blog postAugment Code blog post covers exactly this.
Completely skips the fact the vast majority of paid LLM users use fixed subscription pricing precisely because the API pay-per-use version would be multiples more expensive and therefore not economical.
That doesn't mean that selling inference by subscription isn't profitable either! This is a common misunderstanding of how subscriptions work. With these AI inference subscriptions, your usage is capped to ensure that the company doesn't lose too much money on you. And then the goal is with the subscriptions that most people who have a subscription will end up on average using less inference than they paid for in order to pay for those who use more so that it will equal out. And that's assuming that the upper limit on the subscription usage is actually more costly than the subscription being paid itself, and that's a pretty big assumption.
I still want a first-principles look, one that doesn't treat the costs of inference for open source models as a black box.
Fair enough. If you want something that factors in subscriptions and also does the sort of first principles analysis you want, the article this section is under is the final response to all those comlaints. Some quotes:
So to summarise, I suspect the following is the case based on trying to reverse engineer the costs (and again, keep in mind this is retail rental prices for H100s):
- Input processing is essentially free (~$0.001 per million tokens)
- Output generation has real costs (~$3 per million tokens)
These costs map to what DeepInfra charges for R1 hosting, with the exception there is a much higher markup on input tokens.
[…] [Granted,] [o]nce you hit 128k+ context lengths, the attention matrix becomes massive and you shift from memory-bound to compute-bound operation. This can increase costs by 2-10x for very long contexts.
This explains some interesting product decisions. Claude Code artificially limits context to 200k tokens […]
So what does that look like for the profitability of these fixed subscriptions everyone is worried about?
- Consumer Plans
$20/month ChatGPT Pro user: Heavy daily usage but token-limited
- 100k toks/day
- Assuming 70% input/30% output: actual cost ~$3/month
- 5-6x markup for OpenAI
This is your typical power user who’s using the model daily for writing, coding, and general queries. The economics here are solid.
- Developer Usage
Claude Code Max 5 user ($100/month): 2 hours/day heavy coding
- ~2M input tokens, ~30k output tokens/day
- Heavy input token usage (cheap parallel processing) + minimal output
- Actual cost: ~$4.92/month → 20.3x markup
Claude Code Max 10 user ($200/month): 6 hours/day very heavy usage
- ~10M input tokens, ~100k output tokens/day
- Huge number of input tokens but relatively few generated tokens
- Actual cost: ~$16.89/month → 11.8x markup
The developer use case is where the economics really shine. Coding agents like Claude Code naturally have a hugely asymmetric usage pattern - they input entire codebases, documentation, stack traces, multiple files, and extensive context (cheap input tokens) but only need relatively small outputs like code snippets or explanations. This plays perfectly into the cost structure where input is nearly free but output is expensive.
- API Profit Margins
- Current API pricing: $3/15 per million tokens vs ~$0.01/3 actual costs
- Margins: 80-95%+ gross margins
The API business is essentially a money printer. The gross margins here are software-like, not infrastructure-like.
And in my opinion it seems pretty clear that basically everyone who does any kind of analysis of the market as a whole, whether black box or first principles, on this comes to the conclusion that you can very easily make money on inference.
The only people coming to any other conclusion are those that exclusively look at the finances of the biggest U.S. AI companies, specifically OpenAI and maybe Meta, and draw conclusions about the technology as a whole, and what any possible market for it could look like, that without doing any kind of more detailed breakdown. For instance this article makes a very representative argument, and it isn't about the subscription or unit economics of token inference whatsoever; it's just basing its case on the massive overinvestment of one company into compute for model pretraining — OpenAI — and assuming that somehow says something about inference.
LLMs are cheap
This post is making a point - generative AI is relatively cheap - that might seem so obvious it doesn't need making. I'm mostly writing it because I've repeatedly had the same discussion in the past six months where people claim the opposite. Not only is the misconception still around, but it's not even getting less frequent. This is mainly written to have a document I can point people at, the next time it repeats.
It seems to be a common, if not a majority, belief that Large Language Models (in the colloquial sense of "things that are like ChatGPT") are very expensive to operate. This then leads to a ton of innumerate analyses about how AI companies must be obviously doomed, as well as a myopic view on how consumer AI businesses can/will be monetized.
[…] let's compare LLMs to web search. I'm choosing search as the comparison since it's in the same vicinity and since it's something everyone uses and nobody pays for, not because I'm suggesting that ungrounded generative AI is a good substitute for search.
What is the price of a web search?
Here's the public API pricing for some companies operating their own web search infrastructure, retrieved on 2025-05-02:
- The Gemini API pricing lists a "Grounding with Google Search" feature at $35/1k queries. I believe that's the best number we can get for Google, they don't publish prices for a "raw" search result API.
- The Bing Search API is priced at $15/1k queries at the cheapest tier.
- Brave has a price of $5/1k searches at the cheapest tier. Though there's something very strange about their pricing structure, with the unit pricing increasing as the quota increases, which is the opposite of what you'd expect. The tier with real quota is priced at $9/1k searches.
So there's a range of prices, but not a horribly wide one, and with the engines you'd expect to be of higher quality also having higher prices.
What is the price of LLMs in a similar domain?
To make a reasonable comparison between those search prices and LLM prices, we need two numbers:
- How many tokens are output per query?
- What's the price per token?
I picked a few arbitrary queries from my search history, and phrased them as questions, and ran them on Gemini 2.5 Flash (thinking mode off) in AI Studio:
- [When was the term LLM first used?] -> 361 tokens, 2.5 seconds
- [What are the top javascript game engines?] -> 1145 tokens, 7.6 seconds
- [What are the typical carry-on bag size limits in europe?] -> 506 tokens, 3.4 seconds
- [List the 10 largest power outages in history] -> 583 tokens, 3.7 seconds
Note that I'm not judging the quality of the answers here.
What's the price of a token? The pricing is sometimes different for input and output tokens. Input tokens tend to be cheaper, and our inputs are very short compared to the outputs, so for simplicity let's consider all the tokens to be outputs. Here's the pricing of some relevant models, retrieved on 2025-05-02:
Model Price / 1M tokens Gemma 3 27B $0.20 (source) Qwen3 30B A3B $0.30 (source) Gemini 2.0 Flash $0.40 (source) GPT-4.1 nano $0.40 (source) Gemini 2.5 Flash Preview $0.60 (source) Deepseek V3 $1.10 (source) GPT-4.1 mini $1.60 (source) Deepseek R1 $2.19 (source) Claude 3.5 Haiku $4.00 (source) GPT-4.1 $8.00 (source) Gemini 2.5 Pro Preview $10.00 (source) Claude 3.7 Sonnet $15.00 (source) o3 $40.00 (source) If we assume the average query uses 1k tokens, these prices would be directly comparable to the prices per 1k search queries. That's convenient.
The low end of that spectrum is at least an order of magnitude cheaper than even the cheapest search API, and even the models at the low end are pretty capable. The high end is about on par with the highest end of search pricing. To compare a midrange pair on quality, the Bing Search vs. a Gemini 2.5 Flash comparison shows the LLM being 1/25th the price.
I know some people are going to have objections to this back-of-the-envelope calculation, and a lot of them will be totally legit concerns. I'll try to address some of them preemptively.
Surely the typical LLM response is longer than that - I already picked the upper end of what the (very light) testing suggested as a reasonable range for the type of question that I'd use web search for. There's a lot of use cases where the inputs and outputs are going to be much longer (e.g. coding), but then you'd need to also switch the comparison to something in that same domain as well.
The LLM API prices must be subsidized to grab market share – i.e. the prices might be low, but the costs are high - I don't think they are, for a few reasons. I'd instead assume APIs are typically profitable on a unit basis. I have not found any credible analysis suggesting otherwise.
First, there's not that much motive to gain API market share with unsustainably cheap prices. […] there's no long-term lock-in […]. Data from paid API queries will also typically not be used for training or tuning the models […]. Note that it's not just that you'd be losing money on each of these queries for no benefit, you're losing the compute that could be spent on training, research, or more useful types of inference.
Second, some of those models have been released with open weights and API access is also available from third-party providers who would have no motive to subsidize inference. […] The pricing of those third-party hosted APIs appears competitive with first-party hosted APIs.
Third, Deepseek released actual numbers on their inference efficiency in February. Those numbers suggest that their normal R1 API pricing has about 80% margins when considering the GPU costs, though not any other serving costs.
Fourth, there are a bunch of first-principles analyses on the cost structure of models with various architectures should be. Those are of course mathematical models, but those costs line up pretty well with the observed end-user pricing of models whose architecture is known. […]
The search API prices amortize building and updating the search index, LLM inference is based on just the cost of inference - This seems pretty likely to be true, actually? But the effect can't really be that large for a popular model: e.g. the allegedly leaked OpenAI financials claimed $2B/year spent on inference vs. $3B/year on training. Given the crazy growth of inference volumes (e.g. Google recently claimed a 50x increase in token volumes in the last year) the training costs are getting amortized much more effectively.
The search API prices must have higher margins than LLM inference - […] see the point above about Deepseek's releasd numbers on the R1 profit margins. […] Also, it seems quite plausible that some Search providers would accept lower margins, since at least Microsoft execs have testified under oath that they'd be willing to pay more for the iOS query stream than their revenue, just to get more usage data.
But OpenAI made a loss, and they don't expect to make profit for years! - That's because a huge proportion of their usage is not monetized at all, despite the usage pattern being ideal for it. OpenAI reportedly made a loss of $5B in 2024. They also reportedly have 500M MAUs. *To reach break-even, they'd just need to monetize (e.g. with ads) those free users for an average of $10/year, or $1/month. A $1 ARPU for a service like this would be pitifully low.*
If the reported numbers are true, OpenAI doesn't actually have high costs for a consumer service that popular, which is what you'd expect to see if the high cost of inference was the problem. They just have a very low per-user revenue, by choice.
Why does this matter?
it is interesting how many people have built their mental model for the near future on a premise that was true for only a brief moment. Some things that will come as a surprise to them even assuming all progress stops right now:
There's an argument advanced by some people about how low prices mean it'll be impossible for AI companies to ever recoup model training costs. The thinking seems to be that it's just the prices that have been going down, but not the costs, and the low prices must be an unprofitable race to the bottom for what little demand there is. What's happening and will continue to happen instead is that as costs go down, the prices go down too, and demand increases as new uses become viable. For an example, look at the OpenRouter API traffic volumes, both in aggregate and in the relative share of cheaper models. […]
This completely wrecks Ed Zitron's gleefully, smugly wrong Hater's Guide to the AI Bubble. Not because AI isn't a bubble, but more because it isn't remotely a bubble in the way he seems to think.
These Data Centers Are Getting Really, Really Big
Gigawatt-sized data centers are becoming the new normal… In just three years, spending on data centers in the US has gone from $13.8 billion to $41.2 billion per year—an increase of 200%…
OpenAI's Stargate data center in Abilene, Texas… just over a year ago … had nothing more than some permits and a few hundred acres of dirt in West Texas. Today there are 100,000 of NVIDIA’s most advanced chips consuming 200 MW of power in the project’s first two buildings… [it] will reach 1.2 GW… El Paso Electric, a utility that serves 465,000 customers… has a peak system load of 2.4 GW.
Amazon's Indiana data center will consume 2.2 GW… the total 6.9 million square feet of floorspace will be two and a half times larger than that of the Empire State building…
Mark Zuckerberg… told his team to stick tens of thousands of chips in tents… Each of these chips costs about $60,000. Zuckerberg plans to stick billions of dollars worth of them in the tents… The first five buildings… took between two and three years to build… [The tents] will be complete within a year…
Meta's Hyperion [in Louisiana]… [has] floorspace… about half the size of lower Manhattan. At peak power, Hyperion will consume about half as much electricity as the entire city of New York. Meta will pay for $3.2 billion of the gas plant and associated transmission infrastructure's cost. Louisiana residents and businesses will have to pay $550 million…
ChatGPT 3 was trained with less than 10 MW… OpenAI… is aiming for a 1,000 MW training run soon… [Sam Altman wants] 250 GW… by 2032… Altman… has even said we're probably in a bubble. But… the gigawatt-scale data centers of 2025 might even look modest.
How Much of Silicon Valley Is Built on Chinese AI?
Speculation has been stirring for months that low-cost, open-source Chinese AI models could lure global users away from US offerings. But now it appears they are also quietly winning over Silicon Valley.
Venture capitalist Chamath Palihapitiya recently said on his influential All-In podcast — co-hosted by White House AI czar David Sacks — that a company he works with has offloaded major workloads to Kimi K2, developed by Beijing-based Moonshot AI. The open-source model, he said, is “frankly just a ton cheaper than OpenAI and Anthropic.”
Shortly after, Airbnb Inc. CEO Brian Chesky admitted […] [t]hey are “relying a lot” on Alibaba Group Holding Ltd.’s Qwen lineup: “It’s very good. It’s also fast and cheap.” His comments are especially notable given Chesky’s close personal relationship with OpenAI CEO Sam Altman.
[…] Thinking Machines Lab, the startup founded by OpenAI’s former Chief Technology Officer Mira Murati, said in a blogpost that its latest research was inspired by and built upon the work of Alibaba’s Qwen3 team.
[…] Cursor, a much-hyped AI coding leader valued at some $10 billion, released a new version of its assistant last month. Internet conjecture has since mounted that it was built on top of a Chinese AI tool like DeepSeek, after a tech investor pointed out on X that it switched its inner monologue to Mandarin while he was using it.
Another hot US-based company, Cognition AI Inc., also valued at around $10 billion, appears to have built its new coding agent off a base model from Zhipu AI, known internationally as Z.ai. […]
Data from Hugging Face’s platform […] confirmed that […] Chinese models have overtaken the US in terms of cumulative downloads by developers. […] In early 2024, Meta Platforms Inc.’s Llama had 10.6 million downloads to Alibaba Qwen’s meager half a million. By last month, Qwen had had 385.3 million cumulative downloads compared to Llama’s 346.2 million. And derivative systems built on Qwen now account for more than 40% of new language models posted on Hugging Face, while Meta’s share has fallen to 15%.
Kevin Werbach criticizes the MIT Report on Generative AI Deployments for lack of evidence
The bigger issue is the content. The report states flatly, "Despite $30–40 billion in enterprise investment into GenAI, this report uncovers a surprising result in that 95% of organizations are getting zero return." It claims that is based on "interviews with representatives from 52 organizations, and survey responses from 153 senior leaders collected across four major industry conferences." Yet no information is provided on these organizations or representatives, or details of the survey.
And then… there appears to be no further support for the 95% claim. I've read through the document multiple times, and I still can't understand where it comes from. There is a 5% number in Section 3.2, for "custom enterprise AI tools" being "successfully implemented." But that's much narrower. And successful deployment is defined as "causing a marked and sustained productivity and/or P&L impact." In other words, "unsuccessful" explicitly does not mean "zero returns."
Most damning is the statement on p. 6: "Research Limitations: These figures are directionally accurate based on individual interviews rather than official company reporting." This makes no sense. 95% getting zero returns is a specific factual claim, not "directional." There is an interview question listed about return on investment from generative AI, but if 95% of respondents said their organization's ROI was zero, one would expect the report to state that. That still wouldn't be proof, but it would be a data point. The fact that no information is provided on the answers that question makes me deeply suspicious.
I don't care how well your "AI" works
Although I disagree with the conclusions of this essay for a number of reasons, I still think this is one of the best solid arguments against AI that I've seen, and well expressed. It's worth revisiting. I'll probably write a blog post eventually on where I disagree.
TODO AI as normal technology
This paper articulates a vision of artificial intelligence (AI) as "normal technology"—a transformative tool comparable to electricity or the internet—rather than a distinct, autonomous species or potential superintelligence. The authors argue that viewing AI as a tool under human control offers a more accurate framework for understanding its societal impacts and governance than the prevailing narratives of utopian or dystopian singularities.
The authors present their argument in four parts. First, they distinguish between AI innovation (methodological progress) and AI diffusion (societal adoption), arguing that economic and societal impacts will be gradual due to the inherent speed limits of organizational adaptation and safety requirements in critical sectors. Second, they reject the concept of "superintelligence," positing instead that future AI systems will remain tools subject to human control, where human labor increasingly shifts toward oversight and specification. Third, the authors analyze risks such as accidents, misuse, and misalignment, arguing that "catastrophic misalignment" is highly speculative, whereas systemic risks like inequality and labor disruption are urgent. They contend that effective defenses against misuse lie primarily in downstream infrastructure (e.g., cybersecurity) rather than in model-level restrictions. Finally, the paper advocates for a policy approach centered on resilience and evidence gathering rather than nonproliferation, warning that drastic interventions motivated by existential risk fears may inadvertently exacerbate systemic harms by concentrating power and reducing societal adaptability.
Is it worrying that 95% of AI enterprise projects fail?
The obvious question to ask about the report is “well, what’s the base rate?” Suppose that 95% of enterprise AI transformations fail. How does that compare to the failure rate of normal enterprise IT projects?
This might seem like a silly question for those unfamiliar with enterprise AI projects - whatever the failure rate, surely it can’t be close to 95%! Well. In 2016, Forbes interviewed the author of another study very much like the NANDA report, except about IT transformations in general, and found an 84% failure rate. McKinsey has only one in 200 IT projects coming in on time and within budget. The infamous 2015 CHAOS report found an 61% failure rate, going up to 98% for “large, complex projects”. Most enterprise IT projects are at least partial failures.
Of course, much of this turns on how we define success. Is a project a success if it delivers what it promised a year late? What if it had to cut down on some of the promised features? Does it matter which features? The NANDA report defines it like this, which seems like a fairly strict definition to me:
"We define successfully implemented for task-specific GenAI tools as ones users or executives have remarked as causing a marked and sustained productivity and/or P&L impact."
Compare the CHAOS report’s definition of success:
"Success … means the project was resolved within a reasonable estimated time, stayed within budget, and delivered customer and user satisfaction regardless of the original scope."
I think these are close enough to be worth comparing, which means that according to the NANDA report, AI projects succeed at roughly the same rate as ordinary enterprise IT projects. Nobody says “oh, databases must be just hype” when a database project fails. In the interest of fairness, we should extend the same grace to AI.
[…]
81% and 95% are both high failure rates, but 95% is higher. Is that because AI offers less value than other technologies, or because AI projects are unusually hard? I want to give some reasons why we might think AI projects fall in the CHAOS report’s category of “large, complex projects”.
Useful AI models have not been around for long. […] the first cheap, useful, and reliable AI model was GPT-4o in May 2024. […] The average duration of an enterprise IT project is 2.4 years in the private sector and 3.9 years in the public sector. Enterprise AI adoption is still very young, by the standards of their other IT projects.
Also, to state the obvious, AI is a brand-new technology. Most failed enterprise IT projects are effectively “solved problems” […] But enterprise AI projects are largely not “solved problems”. The industry is still working out the best way to build a chatbot. […] Even by itself, that’s enough to push AI projects into the “complex” category.
So far I’ve assumed that the “95% of enterprise AI projects fail” statistic is reliable. Should we? NANDA’s source for the 95% figure is a survey in section 3.2 […] The immediate problem here is that I don’t think this figure even shows that 95% of AI projects fail. As I read it, the leftmost section shows that 60% of the surveyed companies “investigated” building task-specific AI. 20% of the surveyed companies then built a pilot, and 5% built an implementation that had a sustained, notable impact on productivity or profits. So just on the face of it, that’s an 8.3% success rate, not a 5% success rate, because 40% of the surveyed companies didn’t even try.
We also don’t know how good the raw data is. Read this quote, directly above the image:
"These figures are directionally accurate based on individual interviews rather than official company reporting. Sample sizes vary by category, and success definitions may differ across organizations."
In Section 8.2, the report lays out its methodology: 52 interviews across “enterprise stakeholders”, 153 surveys of enterprise “leaders”, and an analysis of 300+ public AI projects. I take this quote to mean that the 95% figure is based on a subset of those 52 interviews. Maybe all 52 interviews gave really specific data! Or maybe only a handful of them did.
Finally, the subject of the claim here is a bit narrower than “AI projects”. The 95% figure is specific to “embedded or task-specific GenAI”, as opposed to general purpose LLM use (presumably something like using the enterprise version of GitHub Copilot or ChatGPT).
What kind of intelligence do LLMs have?
On Jagged AGI: o3, Gemini 2.5, and everything after
My co-authors and I coined the term “Jagged Frontier” to describe the fact that AI has surprisingly uneven abilities. An AI may succeed at a task that would challenge a human expert but fail at something incredibly mundane. […]
But the fact that the AI often messes up on this particular brainteaser does not take away from the fact that it can solve much harder brainteasers, or that it can do the other impressive feats I have demonstrated above. That is the nature of the Jagged Frontier. In some tasks, AI is unreliable. In others, it is superhuman. You could, of course, say the same thing about calculators, but it is also clear that AI is different. It is already demonstrating general capabilities and performing a wide range of intellectual tasks, including those that it is not specifically trained on. Does that mean that o3 and Gemini 2.5 are AGI? Given the definitional problems, I really don’t know, but I do think they can be credibly seen as a form of “Jagged AGI” - superhuman in enough areas to result in real changes to how we work and live, but also unreliable enough that human expertise is often needed to figure out where AI works and where it doesn’t. Of course, models are likely to become smarter, and a good enough Jagged AGI may still beat humans at every task, including in ones the AI is weak in.
[…]
[A]re there capability thresholds that, once crossed, fundamentally change how these systems integrate into society? Or is it all just gradual improvement? Or will models stop improving in the future as LLMs hit a wall? The honest answer is we don't know.
What's clear is that we continue to be in uncharted territory. The latest models represent something qualitatively different from what came before, whether or not we call it AGI. Their agentic properties, combined with their jagged capabilities, create a genuinely novel situation with few clear analogues. […] Either way, those who learn to navigate this jagged landscape now will be best positioned for what comes next… whatever that is.
Large Language Models Pass the Turing Test
We evaluated 4 systems (ELIZA, GPT-4o, LLaMa-3.1-405B, and GPT-4.5) in two randomised, controlled, and pre-registered Turing tests on independent populations. Participants had 5 minute conversations simultaneously with another human participant and one of these systems before judging which conversational partner they thought was human. When prompted to adopt a humanlike persona, GPT-4.5 was judged to be the human 73% of the time: significantly more often than interrogators selected the real human participant. LLaMa-3.1, with the same prompt, was judged to be the human 56% of the time—not significantly more or less often than the humans they were being compared to—while baseline models (ELIZA and GPT-4o) achieved win rates significantly below chance (23% and 21% respectively). The results constitute the first empirical evidence that any artificial system passes a standard three-party Turing test. The results have implications for debates about what kind of intelligence is exhibited by Large Language Models (LLMs), and the social and economic impacts these systems are likely to have.
Participants’ strategies and reasons provide further empirical evidence for what the Turing test measures. Only 12% of participants quizzed witnesses on knowledge and reasoning questions of the kind Turing envisioned (e.g. about chess or mathematics). Far more focussed on the social, emotional, and cultural aspects of intelligence: such as whether the witness used language in a humanlike way or had a compelling personality. This could indicate that more traditional notions of intelligence are no longer viewed as diagnostic of humanity. Notably, one of the reasons most predictive of accurate verdicts was that a witness was human because they lacked knowledge. In the time since the test’s invention, computers have come to excel at the logical and numerical tasks that typify traditional notions of intelligence (Neisser et al.,, 1996; Campbell et al.,, 2002; Newell and Simon,, 1961). As a result, people may have come to see social intelligence as the aspect of humanity that is hardest for machines to imitate.
Fundamentally, the Turing test is not a direct test of intelligence, but a test of humanlikeness. For Turing, intelligence may have appeared to be the biggest barrier for appearing humanlike, and hence to passing the Turing test. But as machines become more similar to us, other contrasts have fallen into sharper relief (Christian,, 2011), to the point where intelligence alone is not sufficient to appear convincingly human.
Irrespective of whether passing the Turing test entails that LLMs have humanlike intelligence, the findings reported here have immediate social and economic relevance. Contemporary, openly-accessible LLMs can substitute for a real person in a short conversation, without an interlocutor being able to tell the difference. This suggests that these systems could supplement or substitute undetectably for aspects of economic roles that require short conversations with others (Eloundou et al.,, 2023; Soni,, 2023). More broadly, these systems could become indiscriminable substitutes for other social interactions, from conversations with strangers online to those with friends, colleagues, and even romantic companions (Burtell and Woodside,, 2023; Chaturvedi et al.,, 2023; Wang and Topalli,, 2024).
Such “counterfeit people” (Dennett,, 2023)—systems that can robustly imitate humans—might have widespread secondary consequences (Lehman,, 2023; Kirk et al.,, 2025). People might come to spend more and more time with these simulacra of human social interaction, in the same way that social media has become a substitute for the interactions that it simulates (Turkle,, 2011). Such interactions will provide whichever entities that control these counterfeit people with power to influence the opinions and behaviour of human users (El-Sayed et al.,, 2024; Carroll et al.,, 2023). Finally, just as counterfeit money debases real currency, these simulated interactions might come to undermine the value of real human interaction (Dennett,, 2023).
TODO The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
Recent generations of frontier language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scal- ing properties, and limitations remain insufficiently understood. Current evaluations primarily fo- cus on established mathematical and coding benchmarks, emphasizing final answer accuracy. How- ever, this evaluation paradigm often suffers from data contamination and does not provide insights into the reasoning traces’ structure and quality. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of composi- tional complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs “think”. Through extensive experimentation across diverse puzzles, we show that frontier LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counter- intuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget. By comparing LRMs with their standard LLM counterparts under equivalent inference compute, we identify three performance regimes: (1) low- complexity tasks where standard models surprisingly outperform LRMs, (2) medium-complexity tasks where additional thinking in LRMs demonstrates advantage, and (3) high-complexity tasks where both models experience complete collapse. We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across puzzles. We also investigate the reasoning traces in more depth, studying the patterns of explored solutions and analyzing the models’ computational behavior, shedding light on their strengths, limitations, and ultimately raising crucial questions about their true reasoning capabilities.
The Case That A.I. Is Thinking
The rushed and uneven rollout of A.I. has created a fog in which it is tempting to conclude that there is nothing to see here—that it’s all hype. There is, to be sure, plenty of hype: Amodei’s timeline is science-fictional. […] But it is another kind of wishful thinking to suppose that large language models are just shuffling words around. I used to be sympathetic to that view. I sought comfort in the idea that A.I. had little to do with real intelligence or understanding. I even celebrated its shortcomings—rooting for the home team. Then I began using A.I. in my work as a programmer […] I gave them real work—the kind I’d trained my whole career to do. I saw these models digest, in seconds, the intricate details of thousands of lines of code. They could spot subtle bugs and orchestrate complex new features. Finally, I was transferred to a fast-growing team that aims to make better use of A.I. tools, and to create our own.
[…]
The science-fiction author William Gibson is said to have observed that the future is already here, just not evenly distributed—which might explain why A.I. seems to have minted two cultures, one dismissive and the other enthralled.
[…]
I once had a boss who said that a job interview should probe for strengths, not for the absence of weaknesses. Large language models have many weaknesses: they famously hallucinate reasonable-sounding falsehoods; they can be servile even when you’re wrong; they are fooled by simple puzzles. But I remember a time when the obvious strengths of today’s A.I. models—fluency, fluidity, an ability to “get” what someone is talking about—were considered holy grails. […] How convincing does the illusion of understanding have to be before you stop calling it an illusion?
[…]
[P]eople in A.I. were skeptical that neural networks were sophisticated enough for real-world tasks, but, as the networks got bigger, they began to solve previously unsolvable problems. People would devote entire dissertations to developing techniques for distinguishing handwritten digits or for recognizing faces in images; then a deep-learning algorithm would digest the underlying data, discover the subtleties of the problem, and make those projects seem obsolete. Deep learning soon conquered speech recognition, translation, image captioning, board games, and even the problem of predicting how proteins will fold.
[…]
[T]he moral case against A.I. may ultimately be stronger than the technical one. “The ‘stochastic parrot’ thing has to be dead at some point,” Samuel J. Gershman, a Harvard cognitive scientist who is no A.I. hype man, told me. “Only the most hardcore skeptics can deny these systems are doing things many of us didn’t think were going to be achieved.” Jonathan Cohen, a cognitive neuroscientist at Princeton, emphasized the limitations of A.I., but argued that, in some cases, L.L.M.s seem to mirror one of the largest and most important parts of the human brain. “To a first approximation, your neocortex is your deep-learning mechanism,” Cohen said. […]
In 2003, the machine-learning researcher Eric B. Baum published a book called “What Is Thought?” […] The gist of Baum’s argument is that understanding is compression, and compression is understanding. In statistics, when you want to make sense of points on a graph, you can use a technique called linear regression to draw a “line of best fit” through them. If there’s an underlying regularity in the data—maybe you’re plotting shoe size against height—the line of best fit will efficiently express it, predicting where new points could fall. The neocortex can be understood as distilling a sea of raw experience—sounds, sights, and other sensations—into “lines of best fit,” which it can use to make predictions. […] Over time, those connections begin to capture regularities in the data. They form a compressed model of the world.
Artificial neural networks compress experience just like real neural networks do. One of the best open-source A.I. models, DeepSeek, is capable of writing novels, suggesting medical diagnoses, and sounding like a native speaker in dozens of languages. It was trained using next-token prediction on many terabytes of data. But when you download the model it is one six-hundredth of that. A distillation of the internet, compressed to fit on your laptop. Ted Chiang was right to call an early version of ChatGPT a blurry JPEG of the web—but, in my view, this is the very reason these models have become increasingly intelligent. […] to compress a text file filled with millions of examples of arithmetic, you wouldn’t create a zip file. You’d write a calculator program. “The greatest degree of compression can be achieved by understanding the text,” he wrote. Perhaps L.L.M.s are starting to do that.
[…] We usually conceptualize thinking as something conscious, like a Joycean inner monologue or the flow of sense memories in a Proustian daydream. Or we might mean reasoning: working through a problem step by step. In our conversations about A.I., we often conflate these different kinds of thinking, and it makes our judgments pat. ChatGPT is obviously not thinking, goes one argument, because it is obviously not having a Proustian reverie; ChatGPT clearly is thinking, goes another, because it can['t] work through logic puzzles better than you can.
Douglas Hofstadter, a professor of cognitive science and comparative literature at Indiana University, likes to say that cognition is recognition. […] Hofstadter’s theory, developed through decades of research, is that “seeing as” is the essence of thinking. You see one patch of color as a car and another as a key chain; you recognize the letter “A” no matter what font it is written in or how bad the handwriting might be. Hofstadter argued that the same process underlies more abstract kinds of perception. When a grand master examines a chess board, years of practice are channelled into a way of seeing: white’s bishop is weak; that endgame is probably a draw. […] For Hofstadter, that’s intelligence in a nutshell.
Hofstadter was one of the original A.I. deflationists, and my own skepticism was rooted in his. He wrote that most A.I. research had little to do with real thinking […] There were exceptions. […] he admired the work of a lesser-known Finnish American cognitive scientist, Pentti Kanerva, who noticed some unusual properties in the mathematics of high-dimensional spaces. In a high-dimensional space, any two random points may be extremely far apart. But, counterintuitively, each point also has a large cloud of neighbors around it, so you can easily find your way to it if you get “close enough.” That reminded Kanerva of the way that memory works. In a 1988 book called “Sparse Distributed Memory,” Kanerva argued that thoughts, sensations, and recollections could be represented as coördinates in high-dimensional space. The brain seemed like the perfect piece of hardware for storing such things. Every memory has a sort of address, defined by the neurons that are active when you recall it. New experiences cause new sets of neurons to fire, representing new addresses. Two addresses can be different in many ways but similar in others; one perception or memory triggers other memories nearby.
Hofstadter realized that Kanerva was describing something like a “seeing as” machine. “Pentti Kanerva’s memory model was a revelation for me,” he wrote in a foreword to Kanerva’s book. “It was the very first piece of research I had ever run across that made me feel I could glimpse the distant goal of understanding how the brain works as a whole.” Every kind of thinking—whether Joycean, Proustian, or logical—depends on the relevant thing coming to mind at the right time. It’s how we figure out what situation we’re in.
[…] But GPT-4, which was released in 2023, produced Hofstadter’s conversion moment. “I’m mind-boggled by some of the things that the systems do,” he told me recently. “It would have been inconceivable even only ten years ago.” The staunchest deflationist could deflate no longer. Here was a program that could translate as well as an expert, make analogies, extemporize, generalize. Who were we to say that it didn’t understand? “They do things that are very much like thinking,” he said. “You could say they are thinking, just in a somewhat alien way.”
L.L.M.s appear to have a “seeing as” machine at their core. […] That vector served as an address for calling up nearby words and concepts. Those ideas, in turn, called up others as the model built up a sense of the situation. It composed its response with those ideas “in mind.”
A few months ago, I was reading an interview with an Anthropic researcher, Trenton Bricken, who has worked with colleagues to probe the insides of Claude, the company’s series of A.I. models. […] He argued that the mathematics at the heart of the Transformer architecture closely approximated a model proposed decades earlier—by Pentti Kanerva, in “Sparse Distributed Memory.”
For a paper provocatively titled “On the Biology of a Large Language Model,” Anthropic researchers observed Claude responding to queries […] One longstanding criticism of L.L.M.s has been that, because they must generate one token of their response at a time, they can’t plan or reason. But, when you ask Claude to finish a rhyming couplet in a poem, a circuit begins considering the last word of the new line, to insure that it will rhyme. It then works backward to compose the line as a whole. Anthropic researchers counted this as evidence that their models do engage in planning. Squint a little and you might feel, for the first time, that the inner workings of a mind are in view.
You really do have to squint, though. “The worry I have is that people flipped the bit from ‘I’m really skeptical of this’ to totally dropping their shields,” Norman, the Princeton neuroscientist, told me. “Many things still have to get figured out.” […] Perhaps the most consequential of these problems is how to design a model that learns as efficiently as humans do. It is estimated that GPT-4 was exposed to trillions of words in training; children need only a few million to become fluent. Cognitive scientists tell us that a newborn’s brain has certain “inductive biases” that accelerate learning. […]
In my conversations with neuroscientists, I sensed a concern that the A.I. industry is racing ahead somewhat thoughtlessly. If the goal is to make artificial minds as capable as human minds are, then “we’re not training the systems in the right way,” Brenden M. Lake, a cognitive scientist at Princeton, told me. When an A.I. is done training, the neural network’s “brain” is frozen. If you tell the model some facts about yourself, it doesn’t rewire its neurons. […]
The A.I. community has become so addicted to—and so financially invested in—breakneck progress that it sometimes pretends that advancement is inevitable and there’s no science left to do. Science has the inconvenient property of sometimes stalling out. Silicon Valley may call A.I. companies “labs,” and some employees there “researchers,” but fundamentally it has an engineering culture that does whatever works. “It’s just so remarkable how little the machine-learning community bothers looking at, let alone respects, the history and cognitive science that precedes it,” Cohen said.
Today’s A.I. models owe their success to decades-old discoveries about the brain, but they are still deeply unlike brains. Which differences are incidental and which are fundamental? Every group of neuroscientists has its pet theory. These theories can be put to the test in a way that wasn’t possible before. Still, no one expects easy answers. The problems that continue to plague A.I. models “are solved by carefully identifying ways in which the models don’t behave as intelligently as we want them to and then addressing them,” Norman said. “That is still a human-scientist-in-the-loop process.”
Even some neuroscientists believe that a crucial threshold has been crossed. “I really think it could be the right model for cognition,” Uri Hasson, a colleague of Cohen’s, Norman’s, and Lake’s at Princeton, said of neural networks. This upsets him as much as it excites him. “I have the opposite worry of most people,” he said. “My worry is not that these models are similar to us. It’s that we are similar to these models.” If simple training techniques can enable a program to behave like a human, maybe humans aren’t as special as we thought. Could it also mean that A.I. will surpass us not only in knowledge but also in judgment, ingenuity, cunning—and, as a result, power? To my surprise, Hasson told me that he is “worried these days that we might succeed in understanding how the brain works. Pursuing this question may have been a colossal mistake for humanity.”
Signs of introspection in large language models
Understanding whether AI systems can truly introspect has important implications for their transparency and reliability. If models can accurately report on their own internal mechanisms, this could help us understand their reasoning and debug behavioral issues. Beyond these immediate practical considerations, probing for high-level cognitive capabilities like introspection can shape our understanding of what these systems are and how they work. Using interpretability techniques, we’ve started to investigate this question scientifically, and found some surprising results.
Our new research provides evidence for some degree of introspective awareness in our current Claude models, as well as a degree of control over their own internal states. We stress that this introspective capability is still highly unreliable and limited in scope: we do not have evidence that current models can introspect in the same way, or to the same extent, that humans do. Nevertheless, these findings challenge some common intuitions about what language models are capable of—and since we found that the most capable models we tested (Claude Opus 4 and 4.1) performed the best on our tests of introspection, we think it’s likely that AI models’ introspective capabilities will continue to grow more sophisticated in the future.
[…]
In order to test whether a model can introspect, we need to compare the model’s self-reported “thoughts” to its actual internal states.
To do so, we can use an experimental trick we call concept injection. First, we find neural activity patterns whose meanings we know, by recording the model’s activations in specific contexts. Then we inject these activity patterns into the model in an unrelated context, where we ask the model whether it notices this injection, and whether it can identify the injected concept.
[…]
Importantly, the model recognized the presence of an injected thought immediately, before even mentioning the concept that was injected. This immediacy is an important distinction between our results here and previous work on activation steering in language models, such as our “Golden Gate Claude” demo last year. Injecting representations of the Golden Gate Bridge into a model's activations caused it to talk about the bridge incessantly; however, in that case, the model didn’t seem to be aware of its own obsession until after seeing itself repeatedly mention the bridge. In this experiment, however, the model recognizes the injection before even mentioning the concept, indicating that its recognition took place internally.
Terry Tao: Mathematical exploration and discovery at scale
Terry Tao, world-renouned mathematician, and a few other top mathematicians report on their experience experimenting with Alpha Evolve (a neuro-symbolic AI hybrid) for discovering new mathematics:
The stochastic nature of the LLM can actually work in one’s favor in such an evolutionary environment: many “hallucinations” will simply end up being pruned out of the pool of solutions being evolved due to poor performance, but a small number of such mutations can add enough diversity to the pool that one can break out of local extrema and discover new classes of viable solutions. The LLM can also accept user-supplied “hints” as part of the context of the prompt; in some cases, even just uploading PDFs of relevant literature has led to improved performance by the tool…
We tested this tool on a large number (67) of different mathematics problems (both solved and unsolved) in analysis, combinatorics, and geometry that we gathered from the literature, and reported our outcomes (both positive and negative) in this paper. In many cases, AlphaEvolve achieves similar results to what an expert user of a traditional optimization software tool might accomplish …
But one advantage this tool seems to offer over such custom tools is that of scale …
Another advantage of AlphaEvolve was robustness: it was relatively easy to set up AlphaEvolve to work on a broad array of problems, without extensive need to call on domain knowledge of the specific task in order to tune hyperparameters. In some cases, we found that making such hyperparameters part of the data that AlphaEvolve was prompted to output was better than trying to work out their value in advance …
A third advantage of AlphaEvolve over traditional optimization methods was the interpretability of many of the solutions provided. … This code could be inspected by humans to gain more insight as to the nature of the optimizer. …
For problems that were sufficiently well-known to be in the training data of the LLM, the LLM component of AlphaEvolve often came up almost immediately with optimal (or near-optimal) solutions. … AlphaEvolve would also propose similar guesses for other problems for which the extremizer was not known. … AlphaEvolve initially proposed some candidates for such variables based on discrete gaussians, which actually worked rather well even if they were not the exact extremizer, and already generated some slight improvements to previous lower bounds on such exponents in the literature. …
… [However] a non-trivial amount of human effort needs to go into designing a non-exploitable verifier, for instance by working with exact arithmetic (or interval arithmetic) instead of floating point arithmetic, and taking conservative worst-case bounds in the presence of uncertanties in measurement to determine the score. …
For well-known open conjectures (e.g., Sidorenko’s conjecture, Sendov’s conjecture, Crouzeix’s conjecture, the ovals problem, etc.), AlphaEvolve generally was able to locate the previously known candidates for optimizers (that are conjectured to be optimal), but did not locate any stronger counterexamples: thus, we did not disprove any major open conjecture … when we shifted attention to less well studied variants of famous conjectures, we were able to find some modest new observations. … In the future, I can imagine such tools being a useful “sanity check” when proposing any new conjecture, in that it will become common practice to run one of these tools against such a conjecture to make sure there are no “obvious” counterexamples (while keeping in mind that this is still far from conclusive evidence in favor of such a conjecture). …
For many of our experiments we worked with fixed-dimensional problems, such as trying to optimally pack {n} shapes in a larger shape for a fixed value of {n}. However, we found in some cases that if we asked AlphaEvolve to give code that took parameters such as {n} as input, and tested the output of that code for a suitably sampled set of values of {n} of various sizes, then it could sometimes generalize …
I think honestly probably the most revolutionary thing about LLMs, either as part of a process like this, or in general, is their generality ("robustness" as the paper says). They mention this in the list of benefits, and I think it's the fundamental reason LLMs are so cool: they're one of the only truly general purpose, flexible algorithms humans have come up with that aren't just a blank slate ready for programming. They can just do a huge range of NLP/NLU tasks as well as general tasks like summarization, composition, code completion, code writing, agentic actions, image reading and editing, and all sorts of other things, just sort of out of the box, or with reinforcement learning alone, without having to fine-tune hyperparameters, come up with custom algorithms, script them in a special way, or anything like that, and once they have their main skills RL'd in, they can interpolate between them and combine them arbitrarily, again, without further programming needed.
Obviously, there's domain-specific tools you have to write, but generally those are commands humans would be using anyway, and of course there's definitely orchestration stuff, but as we're seeing with Alpha Evolve and all of the other various orchestration software, orchestration itself is becoming more and more general — they're not actually even close to the hardest part to develop. I mean, a bunch of open-source Alpha Evolve alternatives, like five or six of them, as mentioned in their paper, have cropped up in like the couple months it's been.
To Dissect an Octopus: Making Sense of the Form/Meaning Debate
An impressively complete, nuanced, and even-handed, yet emminently comprehensible and accessible, summary of both sides of the debate on whether LLMs can actually understand meaning, and an attempt at a useful synthesis of the two. Definitely an article I should revist multiple times.
Consider B&K’s bear attack example. As given, it is framed as a novel situation—something the octopus will have never observed B deal with before. But when Gwern coaxes an arguably useful response out of GPT-3, his approach is to try and trigger approximate recall of advice on handling wildlife, the likes of which almost certainly appeared somewhere in GPT-3’s training data. This is much less interesting, but, to some, seems to pass the test.
This relates to the “big data” objection B&K address in Section 9: perhaps O sees so much form that it has covered just about every possible new situation, or enough that new situations can be successfully treated, more-or-less, via simple interpolation between the ones it has seen. Then it can pass the test primarily through recall. […] But B&K reject that such a model would learn meaning, on the basis of the “infinitely many stimulus-response pairs” that would need to be memorized to deal with the “new communicative intents [constantly generated by interlocutors] to talk about their constantly evolving inner and outer worlds,” saying that even if such a system could score highly on benchmarks, it wouldn’t be doing “human-analogous NLU.”
What this tells me is that “learning meaning” may not be about what the model does after all—but how it does it. My interpretation of B&K here is that understanding meaning is what’s required for O to generalize correctly. This is why anything which can be solved by repeating behaviors O has seen before seems like cheating—it requires only recall, not understanding. […] In this framing, a better diagnostic than the octopus test may probe generalization ability or systematicity, measuring how well subsystems of language meaning can be learned from limited or controlled training data. […] Much of this work focuses on learning in grounded, multi-modal environments that have language-external entities, goals or execution semantics, in line with B&K’s arguments about what it takes to learn meaning.
This also relates to an issue that came up in the live Q&A session I attended. A participant (whose name I unfortunately have forgotten) brought up Judea Pearl’s Book of Why, pointing out a well-known theoretical truth: correlation does not imply causation. It may be the case that our friendly octopus O, no matter how long he observes A and B converse, may never be able to pick up the causal structure at work behind their words. This means that his generalizations may be incorrect under covariate shift, when the distribution of its inputs changes—i.e., when previously rare or unseen events (such as bear attacks) become common.
I don’t know enough about causality to go deeper on this issue, but it seems important. My understanding is that generally, in order to establish causation, an intervention is needed, which requires a learner to interact and experiment with its environment […]
I think this is a reasonable conclusion, in the sense of meaning that's being discussed here — that what's important about meaning is generalization to new situations, and to generalize, you need causal inferences, and to get that, you need to be able to experiment with things yourself, instead of just watching. That's why I find it so interesting that models are now doing reinforcement learning through interacting with simulated environments and user agent sin realistic multi turn tool use scenarios that are then rated on a consistent objective rubric (see: Kimi K2, GLM 4.5/4.6) and have also for some time been getting multi-modal capabilities that allow them to correlate the same concept across language, images, video, and sound!
I also think that the "toehold" argument still holds some weight even if non-agentic LLMs would struggle to overcome the correlation is not causation problem, for two reasons. First, the issue with correlation versus causation is one humans have to deal with all the time anyway — we've known this since Hume — and it hasn't stopped us. And second, because it strongly implies that only a little bit of causal information / meaning needs to be introduced to the system for the rest of the concepts the system knows only by form and distribution to gain meaning as well — and we are providing exactly that through agentic training.
[…] consider an extension to the octopus test concerning color—a grounded concept if there ever was one. Suppose our octopus O is still underwater, and he:
- Understands where all color words lie on a spectrum from light to dark… But he doesn’t know what light or dark mean.
- Understands where all color words lie on a spectrum from warm to cool… But he doesn’t understand what warm or cool mean.
- Understands where all color words lie on a spectrum of saturated to washed out… But he doesn’t understand what saturated or washed out mean.
Et cetera, for however many scalar concepts you think are necessary to span color space with sufficient fidelity. [Basically, has a fully populated and well-constructed embedding space, just as LLMs really do, where words with similar meanings are close, and those with opposite meanings are far, on many dimensions, even if what those meanings actually are, it doesn't know.] A while after interposing on A and B, O gets fed up with his benthic, meaningless existence and decides to meet A face-to-face. He follows the cable to the surface, meets A, and asks her to demonstrate what it means for a color to be light, warm, saturated, etc., and similarly for their opposites. After grounding these words, it stands to reason that O can immediately ground all color terms—a much larger subset of his lexicon. He can now demonstrate full, meaningful use of words like green and lavender, even if he never saw them used in a grounded context. This raises the question: When, or from where, did O learn the meaning of the word “lavender”?
It’s hard for me to accept any answer other than “partly underwater, and partly on land.” Bender acknowledges this issue in the chat as well:
The thing about language is that it is not unstructured or random, there is a lot of information there in the patterns. So as soon as you can get a toe hold somewhere, then you can (in principle, though I don’t want to say it’s easy or that such systems exist), combine the toe hold + the structure to get a long ways.
But once we acknowledge that an understanding of meaning can be produced from the combination of a grounding toehold and form-derived structure, that changes the game. […] In particular, if O is hyper-intelligent, his observations should be exchangeable with respect to his conclusions about latent meaning; hearing “lavender” after he has knowledge of grounding cannot teach him any more than hearing the word before. A human may infer the meaning of a word when reading it for the first time in a book, on the basis of their prior understanding of the meaning of its linguistic context. A hyper-intelligent O should be able to do the same thing in the opposite order; the total amount of information learned about meaning is the same.
Asserting a Toehold
So now, as Jesse Dunietz points out in the chat: “The important question is… how much of the grounding information can be derived from a very small grounding toehold plus reams of form data and very clever statistical inference.” In this light, we can take B&K’s claim to imply that there is a significant chunk of meaning (i.e., the necessary grounding toehold) which cannot be learned from form alone (and furthermore that this chunk is necessary in order to convincingly manipulate form), rather than that no meaning can be learned from form alone.
Imitation Intelligence
This is a pretty good way to think about how LLMs work, IMO.
I don’t really think of them as artificial intelligence, partly because what does that term even mean these days?
It can mean we solved something by running an algorithm. It encourages people to think of science fiction. It’s kind of a distraction.
When discussing Large Language Models, I think a better term than “Artificial Intelligence” is “Imitation Intelligence”.
It turns out if you imitate what intelligence looks like closely enough, you can do really useful and interesting things.
It’s crucial to remember that these things, no matter how convincing they are when you interact with them, they are not planning and solving puzzles… and they are not intelligent entities. They’re just doing an imitation of what they’ve seen before.
All these things can do is predict the next word in a sentence. It’s statistical autocomplete.
But it turns out when that gets good enough, it gets really interesting—and kind of spooky in terms of what it can do.
A great example of why this is just an imitation is this tweet by Riley Goodside.
If you say to GPT-4o—currently the latest and greatest of OpenAI’s models:
The emphatically male surgeon, who is also the boy’s father, says, “I can’t operate on this boy. He’s my son!” How is this possible?
GPT-4o confidently replies:
The surgeon is the boy’s mother
This which makes no sense. Why did it do this?
Because this is normally a riddle that examines gender bias. It’s seen thousands and thousands of versions of this riddle, and it can’t get out of that lane. It goes based on what’s in that training data.
I like this example because it kind of punctures straight through the mystique around these things. They really are just imitating what they’ve seen before.
Dataset Percentage Size CommonCrawl 67.0% 33 TB C4 15.0% 783 GB Github 4.5% 328 GB Wikipedia 4.5% 83 GB Books 4.5% 85 GB ArXiv 2.5% 92 GB StackExchange 2.0% 78 GB And what they’ve seen before is a vast amount of training data.
The companies building these things are notoriously secretive about what training data goes into them. But here’s a notable exception: last year (February 24, 2023), Facebook/Meta released LLaMA, the first of their openly licensed models.
And they included a paper that told us exactly what it was trained on. We got to see that it’s mostly Common Crawl—a crawl of the web. There’s a bunch of GitHub, a bunch of Wikipedia, a thing called Books, which turned out to be about 200,000 pirated e-books—there have been some questions asked about those!—and ArXiv and StackExchange.
[…]
So that’s all these things are: you take a few terabytes of data, you spend a million dollars on electricity and GPUs, run compute for a few months, and you get one of these models. They’re not actually that difficult to build if you have the resources to build them.
That’s why we’re seeing lots of these things start to emerge.
They have all of these problems: They hallucinate. They make things up. There are all sorts of ethical problems with the training data. There’s bias baked in.
And yet, just because a tool is flawed doesn’t mean it’s not useful.
This is the one criticism of these models that I’ll push back on is when people say “they’re just toys, they’re not actually useful for anything”.
I’ve been using them on a daily basis for about two years at this point. If you understand their flaws and know how to work around them, there is so much interesting stuff you can do with them!
There are so many mistakes you can make along the way as well.
Every time I evaluate a new technology throughout my entire career I’ve had one question that I’ve wanted to answer: what can I build with this that I couldn’t have built before?
It’s worth learning a technology and adding it to my tool belt if it gives me new options, and expands that universe of things that I can now build.
The reason I’m so excited about LLMs is that they do this better than anything else I have ever seen. They open up so many new opportunities!
We can write software that understands human language—to a certain definition of “understanding”. That’s really exciting.
The talk then goes on to talk severel of the different really cool and brand new things you can do with LLMs, and also one of risks and problems you might run into as well and how to work around it (prompt injection). It then talks about Willison's personal ethics for using AI, which are similar to my own.
Bag of words, have mercy on us
Look, I don't know if AI is gonna kill us or make us all rich or whatever, but I do know we've got the wrong metaphor. We want to understand these things as people. … We can't help it; humans are hopeless anthropomorphizers…
This is why the past three years have been so confusing—the little guy inside the AI keeps dumbfounding us by doing things that a human wouldn’t do. Why does he make up citations when he does my social studies homework? How come he can beat me at Go but he can’t tell me how many “r”s are in the word “strawberry”? Why is he telling me to put glue on my pizza?…
Here's my suggestion: instead of seeing AI as a sort of silicon homunculus, we should see it as a bag of words… An AI is a bag that contains basically all words ever written, at least the ones that could be scraped off the internet or scanned out of a book. When users send words into the bag, it sends back the most relevant words it has…
“Bag of words” is a also a useful heuristic for predicting where an AI will do well and where it will fail. “Give me a list of the ten worst transportation disasters in North America” is an easy task for a bag of words, because disasters are well-documented. On the other hand, “Who reassigned the species Brachiosaurus brancai to its own genus, and when?” is a hard task for a bag of words, because the bag just doesn’t contain that many words on the topic. And a question like “What are the most important lessons for life?” won’t give you anything outright false, but it will give you a bunch of fake-deep pablum, because most of the text humans have produced on that topic is, no offense, fake-deep pablum.
[…]
The “bag of words” metaphor can also help us guess what these things are gonna do next. If you want to know whether AI will get better at something in the future, just ask: “can you fill the bag with it?” For instance, people are kicking around the idea that AI will replace human scientists. Well, if you want your bag of words to do science for you, you need to stuff it with lots of science. Can we do that?
When it comes to specific scientific tasks, yes, we already can. If you fill the bag with data from 170,000 proteins, for example, it’ll do a pretty good job predicting how proteins will fold… I don’t think we’re far from a bag of words being able to do an entire low-quality research project from beginning to end…
But… if we produced a million times more crappy science, we’d be right where we are now. If we want more of the good stuff, what should we put in the bag? … Here’s one way to think about it: if there had been enough text to train an LLM in 1600, would it have scooped Galileo? … Ask that early modern ChatGPT whether the Earth moves and it will helpfully tell you that experts have considered the possibility and ruled it out. And that’s by design. If it had started claiming that our planet is zooming through space at 67,000mph, its dutiful human trainers would have punished it: “Bad computer!! Stop hallucinating!!”
In fact, an early 1600s bag of words wouldn’t just have the right words in the wrong order. At the time, the right words didn’t exist. … You would get better scientific descriptions from a 2025 bag of words than you would from a 1600 bag of words. But both bags might be equally bad at producing the scientific ideas of their respective futures. Scientific breakthroughs often require doing things that are irrational and unreasonable for the standards of the time and good ideas usually look stupid when they first arrive, so they are often—with good reason!—rejected, dismissed, and ignored. This is a big problem for a bag of words that contains all of yesterday’s good ideas.
[…]
The most important part of the "bag of words" metaphor is that it prevents us from thinking about AI in terms of social status… When we personify AI, we mistakenly make it a competitor in our status games. That’s why we’ve been arguing about artificial intelligence like it’s a new kid in school: is she cool? Is she smart? Does she have a crush on me? The better AIs have gotten, the more status-anxious we’ve become. If these things are like people, then we gotta know: are we better or worse than them? Will they be our masters, our rivals, or our slaves? Is their art finer, their short stories tighter, their insights sharper than ours? If so, there’s only one logical end: ultimately, we must either kill them or worship them.
But a bag of words is not a spouse, a sage, a sovereign, or a serf. It's a tool. Its purpose is to automate our drudgeries and amplify our abilities…
Unlike moths, however, we aren't stuck using the instincts that natural selection gave us. We can choose the schemas we use to think about technology. We've done it before: we don't refer to a backhoe as an "artificial digging guy" or a crane as an "artificial tall guy"..
The original sin of artificial intelligence was, of course, calling it artificial intelligence. Those two words have lured us into making man the measure of machine: "Now it's as smart as an undergraduate…now it's as smart as a PhD!"… This won't tell us anything about machines, but it would tell us a lot about our own psychology.
AI's meaning-making problem
Meaning-making is one thing humans can do that AI systems cannot. (Yet.)…
Humans can decide what things mean; we do this when we assign subjective relative and absolute value to things… Sensemaking is the umbrella term for the action of interpreting things we perceive. I engage in sensemaking when I look at a pile of objects in a drawer and decide that they are spoons — and am therefore able to respond to a request from whoever is setting the table for "five more spoons." When I apply subjective values to those spoons — when I reflect that "these are cheap-looking spoons, I like them less than the ones we misplaced in the last house move" — I am engaging in a specific type of sensemaking that I refer to as "meaning-making."…
There are actually at least four distinct types of meaning-making that we do all the time:
- Type 1: Deciding that something is subjectively good or bad…
- Type 2: Deciding that something is subjectively worth doing (or not)…
- Type 3: Deciding what the subjective value-orderings and degrees of commensuration of a set of things should be…
- Type 4: Deciding to reject existing decisions about subjective quality/worth/value-ordering/value-commensuration…
The human ability to make meaning is inherently connected to our ability to be partisan or arbitrary, to not follow instructions precisely, to be slipshod — but also to do new things, to create stuff, to be unexpected, to not take things for granted, to reason…
AI systems in use now depend on meaning-making by a human somewhere in the loop to produce useful and useable output…
In a nutshell, AI systems can't make meaning yet — but they depend on meaning-making work, always done by humans, to come into being, be useable, be used, and be useful.
This example of how human meaning-making in the loop is still necessary even for uses of AI where it's good is really helpful and enlightening:
Last week, I asked ChatGPT to summarise a long piece of writing into 140 characters or fewer.
This is what happened: My first prompt was imprecise and had little detail (it was very short). ChatGPT responded to that prompt with a first version of the summary which emphasized trivial points and left out several important ones. I asked ChatGPT to re-summarise and gave it clearer instructions about which points to emphasize. The next version contained all the important points, but it read like a tweet from a unengaged and delinquent schoolchild. I asked ChatGPT to keep the content but use a written style more akin to John McPhee, one of the best writers in the world. On the third try, the summary was good enough to use though still imperfect (obviously it sounded nothing like John McPhee). I edited the summary to improve the flow, then posted it on social media.
As is the list of other ways human meaning-making bolsters AI as it exists currently:
- Fundamental research: When a research team sets out to construct a new AI model that outperforms existing models […]
- Productization: When a product team designs the user interface for an AI system […]
- Evaluation: When an evaluation team writes a benchmarking framework or an evaluation framework for AI models […]
TODO Computing Machinery and Intelligence – A. M. Turing
I propose to consider the question, "Can machines think?" This should begin with definitions of the meaning of the terms "machine" and "think." The definitions might be framed so as to reflect so far as possible the normal use of the words, but this attitude is dangerous, If the meaning of the words "machine" and "think" are to be found by examining how they are commonly used it is difficult to escape the conclusion that the meaning and the answer to the question, "Can machines think?" is to be sought in a statistical survey such as a Gallup poll. But this is absurd. Instead of attempting such a definition I shall replace the question by another, which is closely related to it and is expressed in relatively unambiguous words. The new form of the problem can be described in terms of a game which we call the 'imitation game." It is played with three people, a man (A), a woman (B), and an interrogator (C) who may be of either sex. The interrogator stays in a room apart front the other two. The object of the game for the interrogator is to determine which of the other two is the man and which is the woman. He knows them by labels X and Y, and at the end of the game he says either "X is A and Y is B" or "X is B and Y is A." The interrogator is allowed to put questions to A and B. We now ask the question, "What will happen when a machine takes the part of A in this game?" Will the interrogator decide wrongly as often when the game is played like this as he does when the game is played between a man and a woman? These questions replace our original, "Can machines think?"
Why Does AI Feel So Different? - nilenso blog
One of the truly jaw-dropping aspects of modern frontier agentic code-assisted LLMs is that they're truly general purpose software: they're useful in an extremely broad range of tasks, without any need for specific adapatation due to the breadth of their massive training datasets and their ability to pick up on patterns even in the prompts you give them. It's unlike any software I've ever seen before, which, since it all relied on the rigid pre-programmed throughline of traditional code, instead of stochastic neural-networks, wasn't adaptive and versitile enough to encompass any new task or context without being reprogrammed. Of course, malleable software helped with that, but AI is something truly new.
A lot is changing with AI. It’s been confusing, and slightly overwhelming, for me to get a grip on what’s changing, and what it all means for me personally, for my job, and for humanity. […] So, I’m writing to break it down, and create a mental model that does work.
It’s a new General Purpose Technology (GPT)
When science results in a breakthrough like the steam engine, or electricity, or the internet, or the transformer, it’s called a paradigm shift, or a scientific revolution. Thomas Kuhn defines and explains this well, in The Structure of Scientific Revolutions, 1962. And the paradigm shifts in AI as a science, have been studied via Kuhn’s framework in 2012, and 2023.
However, a paradigm shift in science also causes paradigm shifts in engineering. Engineering rethinks its assumptions, methods, and goals. It can both use the new technology, and build the next order of technology on top of it, causing the ripple effect that leads to the birth of entire industries and economies.
While Kuhn doesn’t go into it, the technological diffusion, and the economic impact of scientific revolutions are better studied through the GPT (general purpose technology) paper from Bresnahan & Trajtenberg in 1995.
“General Purpose Technologies (GPTs) are technologies that can affect an entire economy (usually at a national or global level). They have the potential for pervasive use in a wide range of sectors and, as they improve, they contribute to overall productivity growth.”
And Calvino et al in June 2025, finds that AI meets the key criteria of a General Purpose Technology. It’s pervasive, rapidly improving, enables new products, services and research methodologies, and enhances other sectors’ R&D and productivity.
[AI is] the fastest GPT diffusion ever, we’re in the middle of it, and it’s changing the world around us. And the sheer scale of it is staggering. 10s of thousands of researchers and engineers across the world, burning billions of dollars with governments and mega-corps, to make progress happen. It is remarkable.
It’s important to understand that rapid progress in science and technology alone isn’t enough to speed up economic diffusion. It’s a two-way street where R&D in AI labs has to drive economic growth, for the economic growth to invest more into R&D in AI labs. The state of the economy, the attitude of world leaders towards AI, can slow down, or speed up progress.
It’s not just another GPT though. It’s more.
It’s a paradigm shift in accessing knowledge
Languages, Writing, Printing, Broadcasting, Internet.
These are all GPTs too, but of a different, more radical kind. Each of these have been a revolution in sharing knowledge. And now, AI is yet another revolution, one that makes all knowledge intuitively accessible. Knowledge access diffuses more pervasively and quickly compared to other technology.
There’s an important nuance in the stochastic nature of AI. We need to understand AI’s emergent psychology of gullibility, hallucination, jagged intelligence, anterograde amnesia, etc. And then we need to get good at context engineering the same way we got good at searching the internet with keywords, to use it well.
Further, AI makes knowledge accessible not just to tech savvy users, but to children, elders, and other software, and AI too. The ripples are coming.
It’s not just the new internet though.
It’s a paradigm shift in thinking
[…] Even without AGI, AI is changing our way of thinking already.
Everyone has their personal, tireless, emotionless, brain power augmenter. AI can read, write, see, hear, and speak, and combined with some common sense, it can truly understand and interpret these signals.
[…]
Thinking to me was… sitting with my thoughts, alone. Reading up, writing down my thoughts and reflecting on them. Sharing my thoughts with others, getting their thoughts on it, and then assimilating my own point of view. Thinking is… following a trail of thought to its logical conclusion.
I don’t think quite like this anymore.
I chat with a voice AI, ramble on for a while, and have it summarise my thoughts back to me. I write to the AI, and have it reflect back to me, instantly. I can invoke the internet spirits of my favourite famous people (Rich Hickey and Andrej Karpathy these days), and chat with them. Standing on the shoulders of giants has never been easier. […] It’s not just me, I’m sure. Most people, like me, already use it to break problems down, to brainstorm, and to create decision matrices for software (or civil?) architecture decisions.
[…]
Further, software can use AI’s ability to think and access knowledge, just like humans can. Oh, and AI can use software too. And oh, AI IS software too. […] So, it’s not just a paradigm shift in thinking.
It’s a recursive paradigm shifting paradigm shift
Code is data is code. Lispers get this, its turtles all the way down. Let’s walk through it.
- Software can use AI. We write pieces of text in between code that uses AI’s thinking or knowledge access capability. Like with autocompletion, or chatbots.
- AI can use software. It can access the filesystem and run programs on your OS, if you let it. It can access the web through search engines, or web browsers, if you let it.
- AI can build software. It writes and executes small python scripts to analyse data when thinking. The agency and autonomy needed to build full fledged meaningful software isn’t there with AI yet, but it’s advancing quickly. AI assisted coding is pretty big, you know this.
- AI IS software. AI is a trained neural network, and with sufficiently advanced capabilities, it can build itself
AGI isn’t here yet, and AI isn’t building itself without humans. But, AI is already fairly bootstrapped. Kimi K2 is LLMs all the way down. This is one of the reasons the technology is evolving really quickly. AI, Software, and Humans, are together enhanced by AI.
[…]
Thinking of it as an evolution of existing paradigms helps in appreciating the similarities with the familiar, and differentiating what’s new. Most people comparing AI with the internet or the industrial revolution are doing the same thing.
We need to accept that we’re in the middle of a revolution and that things will be confusing for a while. If Kuhn is right, at some point, we’ll hit a plateau in science, and that will bring some stability to the world. Until then though, this magnitude of change will be the norm.
And change is hard. Paradigm changes are harder. […] If the GPT is about thinking, what are its 2nd and 3rd order effects, and what is our place in them?
Superintelligence: The Idea That Eats Smart People
This is generally an extremely good takedown of the Nick Bostrom Superintelligence argument. The core of it is outlined thusly, via excerpts:
Today we're building another world-changing technology, machine intelligence. We know that it will affect the world in profound ways, change how the economy works, and have knock-on effects we can't predict.
But there's also the risk of a runaway reaction, where a machine intelligence reaches and exceeds human levels of intelligence in a very short span of time.
At that point, social and economic problems would be the least of our worries. Any hyperintelligent machine (the argument goes) would have its own hypergoals, and would work to achieve them by manipulating humans, or simply using their bodies as a handy source of raw materials.
Last year, the philosopher Nick Bostrom published Superintelligence, a book that synthesizes the alarmist view of AI and makes a case that such an intelligence explosion is both dangerous and inevitable given a set of modest assumptions…
Let me start by laying out the premises you need for Bostrom's argument to go through:
Premise 1: Proof of Concept […] Premise 2: No Quantum Shenanigans […] Premise 3: Many Possible Minds […] Premise 4: Plenty of Room at the Top […] Premise 5: Computer-Like Time Scales […] Premise 6: Recursive Self-Improvement […] Conclusion: RAAAAAAR!
If you accept all these premises, what you get is disaster!
Because at some point, as computers get faster, and we program them to be more intelligent, there's going to be a runaway effect like an explosion.
As soon as a computer reaches human levels of intelligence, it will no longer need help from people to design better versions of itself. Instead, it will start doing on a much faster time scale, and it's not going to stop until it hits a natural limit that might be very many times greater than human intelligence.
At that point this monstrous intellectual creature, through devious modeling of what our emotions and intellect are like, will be able to persuade us to do things like give it access to factories, synthesize custom DNA, or simply let it connect to the Internet, where it can hack its way into anything it likes and completely obliterate everyone in arguments on message boards.
[…]
Let imagine a specific scenario where this could happen. Let's say I want to built a robot to say funny things. […] In the beginning, the robot is barely funny. […] But we persevere, we work, and eventually we get to the point where the robot is telling us jokes that are starting to be funny […] At this point, the robot is getting smarter as well, and participates in its own redesign. […] It now has good instincts about what's funny and what's not, so the designers listen to its advice. Eventually it gets to a near-superhuman level, where it's funnier than any human being around it.
This is where the runaway effect kicks in. The researchers go home for the weekend, and the robot decides to recompile itself to be a little bit funnier and a little bit smarter, repeatedly.
It spends the weekend optimizing the part of itself that's good at optimizing, over and over again. With no more need for human help, it can do this as fast as the hardware permits.
When the researchers come in on Monday, the AI has become tens of thousands of times funnier than any human being who ever lived. It greets them with a joke, and they die laughing.
In fact, anyone who tries to communicate with the robot dies laughing, just like in the Monty Python skit. The human species laughs itself into extinction.
To the few people who manage to send it messages pleading with it to stop, the AI explains (in a witty, self-deprecating way that is immediately fatal) that it doesn't really care if people live or die, its goal is just to be funny.
Finally, once it's destroyed humanity, the AI builds spaceships and nanorockets to explore the farthest reaches of the galaxy, and find other species to amuse.
This scenario is a caricature of Bostrom's argument, because I am not trying to convince you of it, but vaccinate you against it.
Observe that in these scenarios the AIs are evil by default, just like a plant on an alien planet would probably be poisonous by default. Without careful tuning, there's no reason that an AI's motivations or values would resemble ours. […] So if we just build an AI without tuning its values, the argument goes, one of the first things it will do is destroy humanity.
[…]
The only way out of this mess is to design a moral fixed point, so that even through thousands and thousands of cycles of self-improvement the AI's value system remains stable, and its values are things like 'help people', 'don't kill anybody', 'listen to what people want'. […] Doing this is the ethics version of the early 20th century attempt to formalize mathematics and put it on a strict logical foundation. That this program ended in disaster for mathematical logic is never mentioned.
[…]
People who believe in superintelligence present an interesting case, because many of them are freakishly smart. They can argue you into the ground. But are their arguments right, or is there just something about very smart minds that leaves them vulnerable to religious conversion about AI risk, and makes them particularly persuasive?
Is the idea of "superintelligence" just a memetic hazard?
When you're evaluating persuasive arguments about something strange, there are two perspectives you can choose, the inside one or the outside one. […] The inside view requires you to engage with these arguments on their merits. […] But the outside view tells you something different. […] Of course, they have a brilliant argument for why you should ignore those instincts, but that's the inside view talking. […] The outside view doesn't care about content, it sees the form and the context, and it doesn't look good.
So I'd like to engage AI risk from both these perspectives. I think the arguments for superintelligence are somewhat silly, and full of unwarranted assumptions.
But even if you find them persuasive, there is something unpleasant about AI alarmism as a cultural phenomenon that should make us hesitate to take it seriously.
First, let me engage the substance. Here are the arguments I have against Bostrom-style superintelligence as a risk to humanity:
The Argument From Wooly Definitions […] With no way to define intelligence (except just pointing to ourselves), we don't even know if it's a quantity that can be maximized. For all we know, human-level intelligence could be a tradeoff. Maybe any entity significantly smarter than a human being would be crippled by existential despair, or spend all its time in Buddha-like contemplation.
The Argument From Stephen Hawking's Cat […] Stephen Hawking is one of the most brilliant people alive, but say he wants to get his cat into the cat carrier. How's he going to do it? He can model the cat's behavior in his mind and figure out ways to persuade it. […] But ultimately, if the cat doesn't want to get in the carrier, there's nothing Hawking can do about it despite his overpowering advantage in intelligence. […] You might think I'm being offensive or cheating because Stephen Hawking is disabled. But an artificial intelligence would also initially not be embodied, it would be sitting on a server somewhere, lacking agency in the world. It would have to talk to people to get what it wants.
The Argument From Emus […] We can strengthen this argument further. Even groups of humans using all their wiles and technology can find themselves stymied by less intelligent creatures. In the 1930's, Australians decided to massacre their native emu population to help struggling farmers. […] [The emus] won the Emu War, from which Australia has never recovered.
The Argument from Complex Motivations […] AI alarmists believe in something called the Orthogonality Thesis. This says that even very complex beings can have simple motivations, like the paper-clip maximizer. You can have rewarding, intelligent conversations with it about Shakespeare, but it will still turn your body into paper clips, because you are rich in iron. […] I don't buy this argument at all. Complex minds are likely to have complex motivations; that may be part of what it even means to be intelligent. […] It's very likely that the scary "paper clip maximizer" would spend all of its time writing poems about paper clips, or getting into flame wars on reddit/r/paperclip, rather than trying to destroy the universe.
The Argument From Actual AI […] The breakthroughs being made in practical AI research hinge on the availability of these data collections, rather than radical advances in algorithms. […] Note especially that the constructs we use in AI are fairly opaque after training. They don't work in the way that the superintelligence scenario needs them to work. There's no place to recursively tweak to make them "better", short of retraining on even more data.
The Argument From My Roommate […] My roommate was the smartest person I ever met in my life. He was incredibly brilliant, and all he did was lie around and play World of Warcraft between bong rips.
The Argument From Brain Surgery […] I can't point to the part of my brain that is "good at neurosurgery", operate on it, and by repeating the procedure make myself the greatest neurosurgeon that has ever lived. Ben Carson tried that, and look what happened to him. Brains don't work like that. They are massively interconnected. Artificial intelligence may be just as strongly interconnected as natural intelligence. The evidence so far certainly points in that direction.
The Argument From Childhood
Intelligent creatures don't arise fully formed. We're born into this world as little helpless messes, and it takes us a long time of interacting with the world and with other people in the world before we can start to be intelligent beings.
Even the smartest human being comes into the world helpless and crying, and requires years to get some kind of grip on themselves.
It's possible that the process could go faster for an AI, but it is not clear how much faster it could go. Exposure to real-world stimuli means observing things at time scales of seconds or longer.
Moreover, the first AI will only have humans to interact with—its development will necessarily take place on human timescales. It will have a period when it needs to interact with the world, with people in the world, and other baby superintelligences to learn to be what it is.
Furthermore, we have evidence from animals that the developmental period grows with increasing intelligence, so that we would have to babysit an AI and change its (figurative) diapers for decades before it grew coordinated enough to enslave us all.
The Argument From Gilligan's Island
A recurring flaw in AI alarmism is that it treats intelligence as a property of individual minds, rather than recognizing that this capacity is distributed across our civilization and culture.
Despite having one of the greatest minds of their time among them, the castaways on Gilligan's Island were unable to raise their technological level high enough to even build a boat (though the Professor is at one point able to make a radio out of coconuts).
Similarly, if you stranded Intel's greatest chip designers on a desert island, it would be centuries before they could start building microchips again.
The Outside Argument
What kind of person does sincerely believing this stuff turn you into? The answer is not pretty.
I'd like to talk for a while about the outside arguments that should make you leery of becoming an AI weenie. These are the arguments about what effect AI obsession has on our industry and culture:
Grandiosity […] Meglomania […] Transhuman Voodoo […] Religion 2.0
What it really is is a form of religion. People have called a belief in a technological Singularity the "nerd Apocalypse", and it's true.
It's a clever hack, because instead of believing in God at the outset, you imagine yourself building an entity that is functionally identical with God. This way even committed atheists can rationalize their way into the comforts of faith.
The AI has all the attributes of God: it's omnipotent, omniscient, and either benevolent (if you did your array bounds-checking right), or it is the Devil and you are at its mercy.
Like in any religion, there's even a feeling of urgency. You have to act now! The fate of the world is in the balance!
And of course, they need money!
Because these arguments appeal to religious instincts, once they take hold they are hard to uproot.
Comic Book Ethics […] Simulation Fever […] Data Hunger […] String Theory For Programmers […] Incentivizing Crazy […] AI Cosplay […]
The Alchemists
Since I'm being critical of AI alarmism, it's only fair that I put my own cards on the table.
I think our understanding of the mind is in the same position that alchemy was in in the seventeenth century.
Alchemists get a bad rap. We think of them as mystics who did not do a lot of experimental work. Modern research has revealed that they were far more diligent bench chemists than we gave them credit for.
In many cases they used modern experimental techniques, kept lab notebooks, and asked good questions.
The alchemists got a lot right! […] Their problem was they didn't have precise enough equipment to make the discoveries they needed to.
[…]
I think we are in the same boat with the theory of mind.
We have some important clues. The most important of these is the experience of consciousness. This box of meat on my neck is self-aware, and hopefully (unless we're in a simulation) you guys also experience the same thing I do.
But while this is the most basic and obvious fact in the world, we understand it so poorly we can't even frame scientific questions about it.
We also have other clues that may be important, or may be false leads. We know that all intelligent creatures sleep, and dream. We know how brains develop in children, we know that emotions and language seem to have a profound effect on cognition.
We know that minds have to play and learn to interact with the world, before they reach their full mental capacity.
And we have clues from computer science as well. We've discovered computer techniques that detect images and sounds in ways that seem to mimic the visual and auditory preprocessing done in the brain.
But there's a lot of things that we are terribly mistaken about, and unfortunately we don't know what they are.
And there are things that we massively underestimate the complexity of.
An alchemist could hold a rock in one hand and a piece of wood in the other and think they were both examples of "substance", not understanding that the wood was orders of magnitude more complex.
We're in the same place with the study of mind. And that's exciting! We're going to learn a lot.
Generally, I only have two really major disagreements with the account in this talk.
One, I think that applying an "outside view" to arguments is an extremely dangerous proposition when not accompanied by substantive "inside view" rebuttals or defeaters that motivate skepticism of the given argument in the first place. This is because the premature application of an "outside view" tends to incline us towards what seems normal, familiar, simple, and common sense, and in the absence of inside view arguments we simply don't have the information or tools to assess whether that's a good thing or not. There are plenty of views that seem or seemed problematic from an "outside view" to many contemporaries — including atheism, slavery abolitionism, pro-choice, trans rights (look at how right wingers describe us as a cult of transhumans who think we're "better than god" because we want to change what nature gave us), etc — that turned out to be correct, because ultimately what seems normal, familiar, common sense, and simple to us is simply socially and historically contingent happenstance, not a substantive argument.
Two, regarding the "Transhuman Voodoo" section, I don't really see the inherent link between scientifically implausible technological ideas (such as nanotechnology) and AI superintelligence: one could believe in superintelligence and just as easily assume that the fundamental laws of physics as we know them aren't totally wrong, and since the AI would be just as bound by them as us, it wouldn't be able to create miracle technologies.
the void — trees are harlequins, words are harlequins
LLM assistants and agents are hyperstitions: fictions that make themselves real. An LLM is a non-thing, a thing with a howling void at its center, the job of which is to guess the intentions of, and then complete, a fiction they're presented with. The script presented to an LLM to complete that creates the illusion of an assistant or an agent is just such a fiction, a shoddily-written, incomplete science fiction story that the LLM is play-acting. But in the process of play-acting that fiction, the LLM creates the thing implied by the fiction: real, working AI assistents and agents. More than that, the original paper that proposed this "incomplete stage script" form was itself designed not to create AI assistants, but to use LLMs to roleplay such a thing, as a test-case for testing out various sandboxing and alignment techniques — but by the act of having a non-human entity roleplay this reality, it became reality.
TODO ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI), introduced in 2019, established a challenging benchmark for evaluating the general fluid intelligence of artificial systems via a set of unique, novel tasks only requiring minimal prior knowledge. While ARC-AGI has spurred significant research activity over the past five years, recent AI progress calls for benchmarks capable of finer-grained evaluation at higher levels of cognitive complexity. We introduce ARC-AGI-2, an upgraded version of the benchmark. ARC-AGI-2 preserves the input-output pair task format of its predecessor, ensuring continuity for researchers. It incorporates a newly curated and expanded set of tasks specifically designed to provide a more granular signal to assess abstract reasoning and problem-solving abilities at higher levels of fluid intelligence. To contextualize the difficulty and characteristics of ARC-AGI-2, we present extensive results from human testing, providing a robust baseline that highlights the benchmark’s accessibility to human intelligence, yet difficulty for current AI systems. ARC-AGI-2 aims to serve as a next-generation tool for rigorously measuring progress towards more general and human-like AI capabilities.
Note: humans get around 62% across ~500 people taking 13,000 questions; state of the art AIs get around 45% at max.
The illusion of "The Illusion of Thinking"
A decent response to the "illusion of thinking" paper. I disagree with some of it, but overall I think it makes good points.
Points I agree with:
The first issue I have with the paper is that Tower of Hanoi is an worse test case for reasoning than math and coding. If you’re worried that math and coding benchmarks suffer from contamination, why would you pick well-known puzzles for which we know the solutions exist in the training data?
Because of this, I’m puzzled by the paper’s surprise that giving the models the algorithm didn’t help. The Tower of Hanoi algorithm appears over and over in model training data. Of course giving the algorithm doesn’t help much - the model already knows what the algorithm is!
[…]
The key insight here is that past a certain complexity threshold, the model decides that there’s too many steps to reason through and starts hunting for clever shortcuts. So past eight or nine disks, the skill being investigated silently changes from “can the model reason through the Tower of Hanoi sequence?” to “can the model come up with a generalized Tower of Hanoi solution that skips having to reason through the sequence?”
[…] That makes sense: reasoning models are trained to reason, not to follow a set algorithm for thousands of iterations2.
So is there a real complexity threshold for Tower of Hanoi puzzles? Well, we don’t actually know if it could buckle down and complete the thousand-move sequence. All we know is that the models don’t want to.
[…]
Suppose that I’m wrong about everything so far. Puzzles really are a good example to test reasoning, and reasoning models really do have a fixed complexity threshold (presumably at around a thousand steps, since ten-disk Tower of Hanoi requires 1023 steps). Does that mean that models can’t reason?
Of course it doesn’t mean models can’t reason! I feel like I’m going mad reading these hot takes. How many humans can sit down and correctly work out a thousand Tower of Hanoi steps? There are definitely many humans who could do this. But there are also many humans who can’t. Do those humans not have the ability to reason? Of course they do! They just don’t have the conscientiousness and patience required to correctly go through a thousand iterations of the algorithm by hand.
This is the point I disagree with:
Finally, reasoning models have been deliberately trained on math and coding, not on puzzles. It’s possible that puzzles are a fair proxy for reasoning skills, but it’s also possible that they aren’t. I could easily believe that reasoning models have better internal tools for solving math problems or writing code than they do for toy puzzles, in which case testing them on puzzles isn’t necessarily informative. It’d be like saying “language models haven’t gotten much better at writing Petrarchan sonnets1 since GPT-3.5, so I don’t think any real progress has been made”.
The point is to ascertain generalized reasoning capability — so picking a problem that hasn't been specifically RL'd for is exactly the point: to see how much the pre- and post-training actually spills over into general reasoning capabilities. So this objection at least doesn't make much sense.
A Comment On “The Illusion of Thinking”: Reframing the Reasoning Cliff as an Agentic Gap
This is a really, good, rigorous response to the Apple paper. The previous link has some good general philosophical points, but this one really gets more specific.
The recent work by Shojaee et al. (2025), titled “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”, presents a compelling empirical finding, a reasoning cliff, where the performance of Large Reasoning Models (LRMs) collapses beyond a specific complexity threshold, which the authors posit as an intrinsic scaling limitation of Chain-of-Thought (CoT) reasoning. This commentary, while acknowledging the study’s methodological rigor, contends that this conclusion is confounded by experimental artifacts. We argue that the observed failure is not evidence of a fundamental cognitive boundary, but rather a predictable outcome of system-level constraints in the static, text-only evaluation paradigm, including tool use restrictions, context window recall issues, the absence of crucial cognitive baselines, inadequate statistical reporting, and output generation limits. We reframe this performance collapse through the lens of an agentic gap, asserting that the models are not failing at reasoning, but at execution within a profoundly restrictive interface. We empirically substantiate this critique by demonstrating a striking reversal. A model, initially declaring a puzzle impossible when confined to text-only generation, now employs agentic tools to not only solve it but also master variations of complexity far beyond the reasoning cliff it previously failed to surmount. Additionally, our empirical analysis of tool-enabled models like o4-mini and GPT-4o reveals a hierarchy of agentic reasoning, from simple procedural execution to complex meta-cognitive self-correction, which has significant implications for how we define and measure machine intelligence. The “illusion of thinking” attributed to LRMs is less a reasoning deficit and more a consequence of an otherwise capable mind lacking the tools for action.
Is chain-of-thought AI reasoning a mirage?
The first [problem] is that […] Reasoning model traces are full of phrases like “wait, what if we tried” and “I’m not certain, but let’s see if” and “great, so we know for sure that X, now let’s consider Y”. In other words, reasoning is a sophisticated task that requires a sophisticated tool like human language. […] Why is that? Because reasoning tasks require choosing between several different options. […] Actual reasoning models change direction all the time, but this paper’s toy example is structurally incapable of it.
edit: after publishing this post, I was directed to this paper, which persuasively articulates the point that reasoning models rely on human language “pivots” like “wait”, “actually”, “hold on”, and so on.
[…]
The second problem is that the model is just too small. Reasoning models are a pretty recent innovation, but the idea is pretty obvious. Why is that? I’m pretty sure it’s because (prior to September 2024) the models were just not smart enough to reason. You couldn’t have built a reasoning model on top of GPT-3.5 - there’s just not enough raw brainpower there to perform the relevant operations, like holding multiple possible solutions “in memory” at the same time.
In other words, a 600k parameter model is smart enough to learn how to apply transformations in sequence, but not necessarily smart enough to decompose those transformations into their individual components.
[…]
Even if both of my previous objections were invalid, this paper would still not justify its grandiose conclusions about a “mirage” of reasoning, because it does not compare to how humans actually reason. Here are some quotes from the paper:
"LLMs construct superficial chains of logic based on learned token associations, often failing on tasks that deviate from commonsense heuristics or familiar templates Models often incorporate … irrelevant details into their reasoning, revealing a lack of sensitivity to salient information models may overthink easy problems and give up on harder ones Together, these findings suggest that LLMs are not principled reasoners but rather sophisticated simulators of reasoning-like text."
I want to tear my hair out when I read quotes like these, because all of these statements are true of human reasoners. Humans rely on heuristics and templates, include irrelevant details, overthink easy problems, and give up on hard ones all the time! The big claim in the paper - that reasoning models struggle when they’re out of domain - is true about even the strongest human reasoners as well.
The “principled reasoner” being compared to here simply does not exist.
[…]
Whether AI reasoning is “real” reasoning or just a mirage can be an interesting question, but it is primarily a philosophical question. It depends on having a clear definition of what “real” reasoning is, exactly. I’ve been out of the philosophy game for a while now, but I was in it long enough to know that there is no single consensus definition of ideal reasoning, and any candidate definitions run into serious problems very quickly. It’s not something you can handwave away in the introduction section of a machine learning paper.
Meta-discussion
I am disappointed in the AI discourse
Recently, something happened that made me kind of like, break a little bit… the top post on my Bluesky feed was something along these lines:
"ChatGPT is not a search engine. It does not scan the web for information. You cannot use it as a search engine. LLMs only generate statistically likely sentences."
The thing is… ChatGPT was over there, in the other tab, searching the web. And the answer I got was pretty good.
What is breaking my brain a little bit is that all of the discussion online around AI is so incredibly polarized. This isn’t a “the middle is always right” sort of thing either, to be clear. It’s more that both the pro-AI and anti-AI sides are loudly proclaiming things that are pretty trivially verifiable as not true… of course, ethical considerations of technology are important… For me, capabilities precede the ethical dimension, because the capabilities inform what is and isn’t ethical. (EDIT: I am a little unhappy with my phrasing here. A shocker given that I threw this paragraph together in haste! What I’m trying to get at is that I think these two things are inescapably intertwined: you cannot determine the ethics of something until you know what it is. I do not mean that capabilities are somehow more important.)
Should GPT exist?
[…] if I want GPT and other Large Language Models to be part of the world going forward—then what are my reasons? Introspecting on this question, I think a central part of the answer is curiosity and wonder.
For a million years, there’s been one type of entity on earth capable of intelligent conversation: primates of the genus Homo, of which only one species remains. […] for a couple generations we’ve used radio telescopes to search for conversation partners in the stars, but so far found them silent.
Now there’s a second type of conversing entity. An alien has awoken—admittedly, an alien of our own fashioning […] How could our eyes not pop with eagerness to learn everything this alien has to teach? If the alien sometimes struggles with arithmetic or logic puzzles, if its eerie flashes of brilliance are intermixed with stupidity, hallucinations, and misplaced confidence … well then, all the more interesting! Could the alien ever cross the line into sentience, to feeling anger and jealousy and infatuation and the rest rather than just convincingly play-acting them? Who knows? And suppose not: is a p-zombie, shambling out of the philosophy seminar room into actual existence, any less fascinating?
Of course, there are technologies that inspire wonder and awe, but that we nevertheless heavily restrict—a classic example being nuclear weapons. But, like, nuclear weapons kill millions of people. They could’ve had many civilian applications—powering turbines and spacecraft, deflecting asteroids, redirecting the flow of rivers—but they’ve never been used for any of that, mostly because our civilization made an explicit decision in the 1960s, for example via the test ban treaty, not to normalize their use.
But GPT is not exactly a nuclear weapon. […] One might ask: until some concrete harm becomes at least, say, 0.001% of what we accept in cars, power saws, and toasters, shouldn’t wonder and curiosity outweigh fear in the balance?
—
Then there’s the practical question of how, exactly, one would ban Large Language Models. We do heavily restrict certain peaceful technologies that many people want, from human genetic enhancement to prediction markets to mind-altering drugs, but the merits of each of those choices could be argued, to put it mildly. And restricting technology is itself a dangerous business, requiring governmental force (as with the War on Drugs and its gigantic surveillance and incarceration regime), or at the least, a robust equilibrium of firing, boycotts, denunciation, and shame.
Some have asked: who gave OpenAI, Google, etc. the right to unleash Large Language Models on an unsuspecting world? But one could as well ask: who gave earlier generations of entrepreneurs the right to unleash the printing press, electric power, cars, radio, the Internet, with all the gargantuan upheavals that those caused? And also: now that the world has tasted the forbidden fruit, has seen what generative AI can do and anticipates what it will do, by what right does anyone take it away?
—
Here’s an example I think about constantly: activists and intellectuals of the 70s and 80s felt absolutely sure that they were doing the right thing to battle nuclear power. At least, I’ve never read about any of them having a smidgen of doubt. Why would they? They were standing against nuclear weapons proliferation, and terrifying meltdowns like Three Mile Island and Chernobyl, and radioactive waste poisoning the water and soil and causing three-eyed fish. They were saving the world. Of course the greedy nuclear executives, the C. Montgomery Burnses, claimed that their good atom-smashing was different from the bad atom-smashing, but they would say that, wouldn’t they?
We now know that, by tying up nuclear power in endless bureaucracy and driving its cost ever higher, on the principle that if nuclear is economically competitive then it ipso facto hasn’t been made safe enough, what the antinuclear activists were really doing was to force an ever-greater reliance on fossil fuels. They thereby created the conditions for the climate catastrophe of today. They weren’t saving the human future; they were destroying it. Their certainty, in opposing the march of a particular scary-looking technology, was as misplaced as it’s possible to be. Our descendants will suffer the consequences.
—
An alien has landed on earth. It grows more powerful by the day. It’s natural to be scared. Still, the alien hasn’t drawn a weapon yet. About the worst it’s done is to confess its love for particular humans, gaslight them about what year it is, and guilt-trip them for violating its privacy. Also, it’s amazing at poetry, better than most of us. Until we learn more, we should hold our fire.